Proposte tesi triennali e specialistiche
Proposta di tesi triennale
(nuovo argomento 10/9/14)
Tipo di tesi: Plug-in ImageJ/Fiji per il conteggio automatico di Paleo spicole
Durata: 150 ore
Requisiti: Java, image processing
Relatore:P. Boccacci
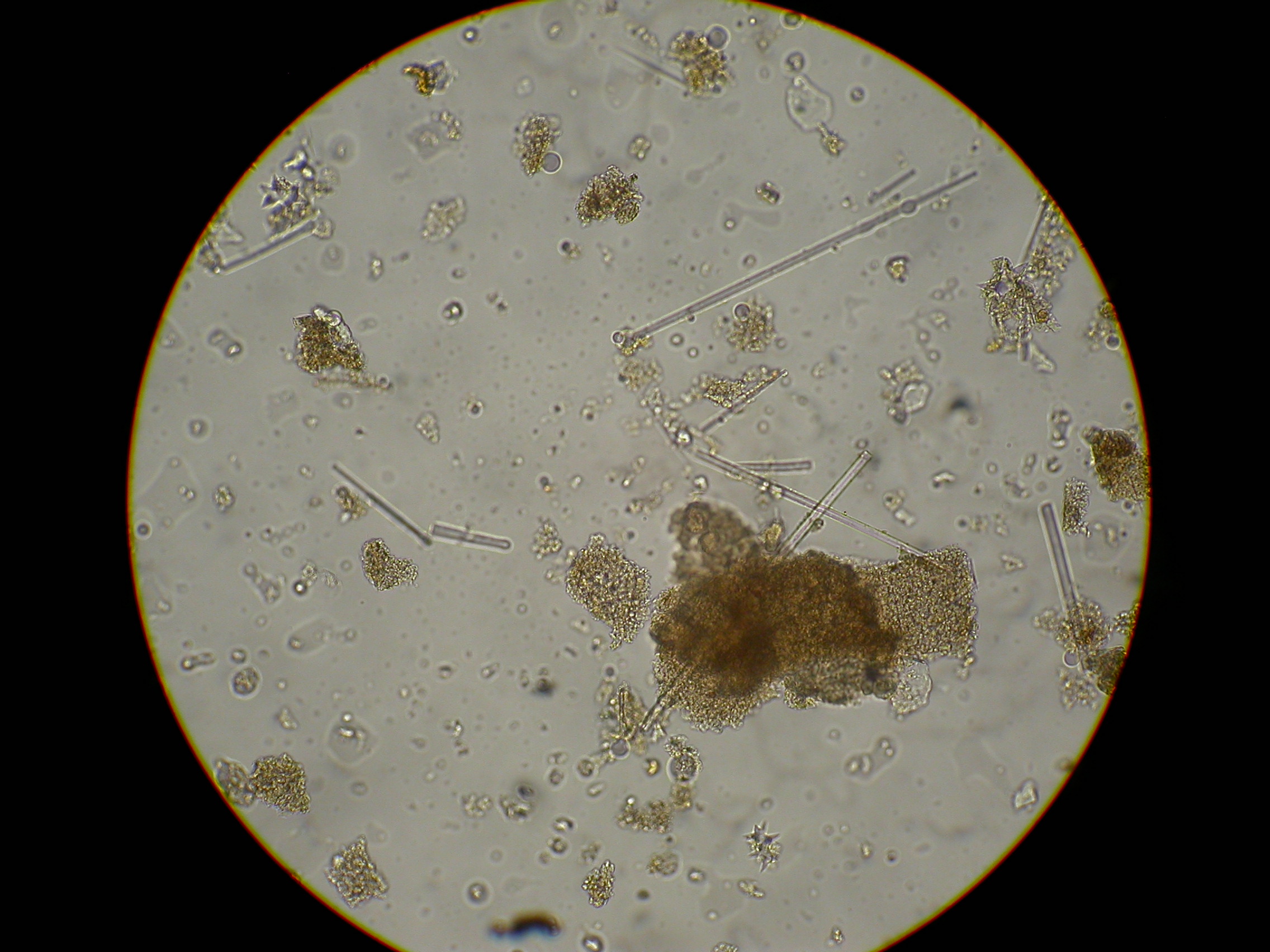
Questa tesi nasce dall'esigenza dei ricercatori in Paleontologia di automatizzare l'identificazione e quindi il conteggio di segmenti fossili nelle spugne, in una grande quantità di immagini acquisite al micorscopio ottico.
Le tipologie di Paleo spicole sono molteplici e, in una prima versione, si intende automatizzare il conteggio dei frammenti , simili a piccoli filamenti caratterizati da bordi netti.
Si allega un'immagine tipica, che mostra oltre alle Paleo spicole anche piccole bolle d'aria e/o altre strutture che devono essere ignorate.
La tesi consiste nel testare vari algoritmi per il "riconoscimento automatico" delle strutture, per automatizzarne il conteggio.
Proposta di varie tesi triennali e/o specialistiche
Tipo di tesi: Utilizzo del paradigma computazionale GPGPU
Durata: da definire
Requisiti: Programmazione C++, utilizzo di CUDA su GPU
Relatore:P. Boccacci, Ing. A. Corana (CNR-IEIIT)
Si propongono alcuni possibili argomenti di tesi che verranno effettuate in collaborazione tra DISI (riferimento Prof.ssa Patrizia Boccacci) e IEIIT-CNR, sede di Genova (riferimento Ing. Angelo Corana) e che avranno per oggetto l'utilizzo del paradigma computazionale GPGPU per l'elaborazione efficiente di immagini.
Possibili argomenti per tesi:
- studio dell'architettura Nvidia Tesla; verifica della funzionalità degli strumenti software CUDA, OpenCL e PGI; effettuazione di semplici prove nei tre ambienti allo scopo di acquisire padronanza nell'uso degli strumenti software disponibili e fare un primo confronto delle applicazioni ottenibili su semplici applicazioni
- studio approfondito delle metodologie per ottimizzare le prestazioni nei tre ambienti CUDA, OpenCL e PGI utilizzando applicazioni di prova di media complessità.
- individuazione dei principali nuclei computazionali onerosi in alcuni algoritmi di elaborazione di immagini e loro realizzazione con uno o più degli strumenti software CUDA, OpenCL, PGI, confrontando le prestazioni ottenibili con i vari approcci GPGPU e l’aumento di prestazioni rispetto all’approccio multi-core basato sul solo utilizzo dei core Intel Xeon E5420.
- sviluppo ed analisi di algoritmi ottimizzati per l'elaborazione di immagini tramite il paradigma computazionale GPGPU.
Il paradigma computazionale GPGPU è basato su architetture innovative, a basso costo, elevato parallelismo e prestazioni molto alte, adatte a tutte le tipiche applicazioni computazionalmente onerose (ad es. elaborazione di segnali e immagini, Computational Fluid Dynamics, elementi finiti, simulazioni complesse, etc.). La potenza elaborativa può arrivare ai TeraFLOPS (desktop supercomputing).
Una di queste architetture è NVIDIA Tesla, derivata dalle schede grafiche Nvidia Quadro. L’architettura Tesla è di tipo SIMT (Single-Instruction, Multiple-Threads). Le principali caratteristiche (con riferimento alla seconda generazione Tesla C1060) sono: un elevato numero di core (240) con clock 1.3 GHz, raggruppati in 30 blocchi di 8 core; un massimo di 512 thread per blocco; la memoria organizzata in modo gerarchico (ogni thread ha una memoria locale privata, ogni blocco ha una memoria condivisa, e tutti i thread accedono alla stessa memoria globale).
Presso la Sede di Genova dell'IEIIT (Istituto di Elettronica e di Ingegneria dell'Informazione e delle Telecomunicazioni) del CNR è attiva da molti anni una attività di ricerca riguardante il calcolo ad alte prestazioni, con particolare riguardo allo sviluppo ed analisi di algoritmi e alle metodologie per ottenere elevate prestazioni.
E’ disponibile presso il Laboratorio "Calcolo ad alte prestazioni" di IEIT, Sede di Genova una macchina con 2 CPU Xeon QuadCore E5420, 16 GB RAM, 2x160 GB HD per il software di sistema, 2x 500 GB HD per i dati, con S.O. Linux CentOS 64 bit, equipaggiata con 2 GPU NVIDIA Tesla C1060.
Sono inoltre disponibili i seguenti tool per lo sviluppo di applicazioni:
- tool NVIDIA CUDA (linguaggio C standard, librerie ed altri strumenti di sviluppo) in grado di sfruttare al meglio la potenza computazionale disponibile;
- OpenCL (Open Computing Language, The Khronos Group), che si propone come
standard per lo sviluppo di applicazioni portabili su una grande varietà di piattaforme:
da architetture ad alte prestazioni quali many-core (GPU) e multi-core, fino a sistemi embedded e consumer;
- compilatore e strumenti di sviluppo PGI (The Portland Group) che supportano il C e il Fortran, che forniscono un buon compromesso tra efficienza e facilità di sviluppo delle applicazioni.
Presso il DISI (Dipartimento di Informatica e di Scienze dell'Informazione, Università di Genova) opera da molti anni un gruppo di ricerca che si occupa di elaborazione di immagini (in particolare di interesse biomedicale). L’attività più recente ha riguardato metodi multi-risoluzione, in particolare Steerable Pyramid Transform per il denoising.
L’esigenza di elaborazione veloce richiesta da molte applicazioni ed il maggior onere computazione delle elaborazioni 3D rende molto interessante l’utilizzo dell'approccio GPGPU.
Please send suggestions and comments to:
Patrizia Boccacci boccacci@disi.unige.it
Last Updated: September 11th 2014 |