Scopo di questo capitolo é lo studio della struttura delle macchine convenzionali, mirato soprattutto alla comprensione delle motivazioni che stanno dietro ad alcune scelte di carattere architetturale e sistemistico ed alla familiarizzazione con i temi e problemi legati alla progettazione ed all'uso efficiente dei sistemi.
Cominceremo con una discussione generale di alcune funzionalità di base
delle macchine convenzionali moderne, e proseguiremo poi con l'esame
dettagliato di un "esempio didattico".
Il riferimento ad una macchina diversa da quelle più diffuse sul
mercato é intenzionale: si vuole in questo modo mettere in evidenza che
i problemi trattati non sono specifici di una particolare realizzazione ma
sono comuni a molte macchine.
Si vuole anche evitare una sterile "rincorsa" dell'ultima moda in
fatto di tecnologie per evitare di evidenziare troppo alcuni dettagli poco
significativi dal punto di vista concettuale, rischiando di perdere di vista
problematiche di fondo di maggior interesse concettuale.
Mentre nel caso dell'esempio di Macchina di Von Neumann si voleva semplicemente evidenziare l'idea di macchina programmabile dotata di memoria RAM, prescindendo completamente da qualsiasi considerazione sulla effettiva usabilità della macchina stessa, ritorniamo ora a parlare di macchine convenzionali dal punto di vista di chi sta cercando di definire una macchina che, pur rimanendo molto semplice in modo da prestarsi a delle considerazioni di carattere didattico, sia comunque in grado di rispondere in modo ragionevole alle esigenze di utilizzazione per l'esecuzione di programmi. I limiti più evidenti che abbiamo potuto toccare con mano quando abbiamo provato a definire dei programmi per la macchina di Von Neumann erano legati alla necessità di usare programmi automodificanti per risolvere una serie di problemi di rilevante interesse pratico, quali la possibilità di accedere successivamente ad un insieme di elementi di un vettore, oppure la possibilità di ritornare ad un programma interrotto a seguito dell'attivazione di una estensione procedurale.
Tutte le macchine convenzionali moderne offrono una soluzione a questi problemi che evita di dover ricorrere al "trucco" dei programmi automodificanti (poco gradito ai programmatori in quanto si presta facilmente a commettere errori di programmazione difficilmente individuabili). Le principali soluzioni adottate consistono nel definire un insieme di modi di indirizzamento della memoria molto più ricco e sofisticato di quello della macchina di Von Neumann. L'aggiunta di ulteriori registri oltre all'accumulatore consente poi di realizzare un metodo semplice ed efficace per interrompere l'esecuzione di un programma sequenziale, passare all'esecuzione di una estensione procedurale, e poi riprendere l'esecuzione del programma principale dal punto in cui era stato interrotto come operazioni primitive della macchina convenzionale, invece che come "trucchi" a livello di programmazione. Infine occorre specificare le modalità di interazione con i dispositivi di ingresso e uscita dei dati che consentano di utilizzare il nostro sistema di calcolo in un ambiente interattivo.
Contrariamente a quanto potrebbe apparire dall'esempio della macchina di Von Neumann (ed anche, purtroppo, dall'analisi di alcune macchine commerciali) l'insieme delle istruzioni fornite al livello 2 non é determinato in modo piu' o meno casuale elencando le funzioni elementari di manipolazione di rappresentazioni binarie che possono venire in mente ad un progettista piu' o meno fantasioso. La progettazione dell'insieme delle istruzioni che definisce una macchina convenzionale (insieme alla scelta della loro codifica binaria in memoria) é una attività cruciale per determinare il successo di un sistema, sia in termini di facilità di uso della macchina, sia in termini di organizzazione della sua microarchitettura e quindi del costo e delle prestazioni ottenibili.
Normalmente l'insieme delle istruzioni viene suddiviso in sottoinsiemi di istruzioni destinate a risolvere problemi diversi. In una architettura moderna si possono sempre trovare delle istruzioni di tipo "aritmetico", di tipo "logico", di "controllo di flusso" dell'esecuzione, di gestione di risorse di calcolo, di trattamento delle eccezioni, di spostamento delle informazioni e (a volte) di ingresso ed uscita dei dati. Molte istruzioni fanno esplicito riferimento ad operandi (per esempio una istruzione di somma fa normalmente riferimento a due addendi ed a un risultato, ossia a tre operandi) di tipo parametrico (ossia ulteriormente definibili a parte, per esempio specificando particolari indirizzi di memoria, senza per questo cambiare il principio di funzionamento dell'istruzione stessa). La specifica di questi parametri avviene normalmente mediante l'uso di una modalità di indirizzamento predefinita. Di solito nella progettazione dell'insieme delle istruzioni si tende a separare il problema di definizione delle istruzioni aritmetiche e logiche (ossia il tipo di manipolazioni che possono essere applicate a degli operandi) da quello della definizione dei modi di indirizzamento per individuare tali operandi.
Una volta definito l'insieme delle istruzioni ed i modi di indirizzamento degli operandi, occorre poi definire una codifica binaria per la rappresentazione in RAM delle istruzioni. La definizione della codifica delle istruzioni non é una operazione semplice ed indolore. Anzi, molto spesso é proprio la possibilità di definire una codifica semplice ed efficente a porre dei vincoli sulla introduzione di una istruzione e/o di un particolare modo di indirizzamento per i suoi operandi. Spesso l'obiettivo primario della progettazione della codifica delle istruzioni é quello di risparmiare bit, in modo da ridurre la quantità di memoria necessaria per contenere un programma ed il tempo necessario per completare le fasi di fetch, e quindi di aumentare la velocità di esecuzione dei programmi. Non esistono neppure criteri universalmente accettati per definire quale potrebbe essere una codifica ottimale delle istruzioni di una macchina convenzionale: mentre in alcuni casi i progettisti tendono a usare sempre ed in ogni caso il numero minimo di bit per ottimizzare la codifica di una singola istruzione, in altri casi tendono a privilegiare l'uniformità di rappresentazione di istruzioni diverse (per esempio seguendo il criterio: tutte le istruzioni rappresentate sempre con lo stesso numero prefissato di bit).
In generale, vengono sempre usati codici ad espansione per combinare le informazioni relative a quale istruzione si vuole eseguire e su quali operandi essa deve agire, in un modo ritenuto ottimale dal progettista.
Normalmente le istruzioni di tipo aritmetico/logico di una macchina convenzionale fanno riferimento ad un numero prestabilito di operandi. Per esempio, nel caso di una istruzione di somma, potremmo definire tre operandi separatamente: i due addendi (operandi in ingresso alla istruzione) ed il risultato (operando in uscita, calcolato durante l'esecuzione dell'istruzione). La rappresentazione binaria di ciascuno di questi operandi coinvolti nella esecuzione di una istruzione può essere memorizzata in un registro interno alla CPU oppure in una cella di memoria RAM. La definizione dei modi di indirizzamento serve appunto per chiarire le modalità di individuazione del registro o cella di memoria che deve essere coinvolta in una operazione di lettura o scrittura per portare a termine l'esecuzione dell'istruzione. Cominciamo con l'elenco di 7 modi di indirizzamento diversi, poi discuteremo la loro utilità per risolvere alcuni problemi di organizzazione dei programmi da eseguire su una macchina convenzionale.
L'uso dei modi di indirizzamento indiretto, indicizzato e autoincremento consentono di ripetere l'esecuzione della stessa istruzione per accedere a celle di memoria diverse senza cambiare il codice operativo delle istruzioni stesse (rendendo inutile il ricorso a tecniche di programmazione di tipo automodificanti). In particolare, il modo di indirizzamento indicizzato può essere visto come un modo più generale di indirizzamento che comprende come casi particolari anche il modo diretto ed il modo indiretto mediante registro (il primo viene simulato facendo riferimento ad un registro contenente il valore costante 0, il secondo facendo uso della costante 0 nel modo indicizzato).
Nella presentazione dell'esempio di Macchina di Von Neumann avevamo enfatizzato la possibilità di "mischiare" in modo completamente arbitrario e selvaggio le celle di memoria destinate a contenere i dati con quelle destinate a contenere il codice operativo delle istruzioni. Tale caratteristica, tuttavia, non costituisce necessariamente un vantaggio, ed in pratica può risultare invece molto più conveniente porre un freno alla fantasia del programmatore e forzarlo ad un uso molto piu' ordinato e razionale dello spazio degli indirizzi in RAM. Da qui in poi cercheremo quindi di privilegiare un uso "ordinato" delle celle di memoria RAM, cominciando col distinguere le celle usate per il codice da quelle usate per i dati. In oltre considereremo separatamente il codice ed i dati di un programma P1 da quelli di un programma P2 destinato a risolvere un altro problema oppure a costituire una estensione procedurale utilizzata da P1.
In particolare, cerchiamo ora di risolvere il problema di consentire a due programmi diversi P1 e P2 di accedere ai loro propri dati in un modo semplice, uniforme, ed indipendente dalla presenza dei dati relativi ad altri programmi sempre allocati in RAM. Il modello di uso dello spazio di memoria a cui possiamo far riferimento (chiamato organizzazione di tipo stack) é quello della sovrapposizione di nuovi fogli di carta (o quaderni) su di una scrivania. Supponiamo di essere seduti ad una scrivania e di studiare su una copia cartacea di questi appunti del corso di Architettura degli Elaboratori. Ad un certo punto arriva un conoscente con una copia di un quotidiano e depositando la copia del quotidiano sopra i fogli degli appunti che stavamo leggendo ci chiede dare un'occhiata alla pagina degli spettacoli per decidere se andare a teatro l'indomani sera. A questo punto il quotidiano copre gli appunti di Architettura e ci costringe a tralasciare per un po' di tempo lo studio e prestare attenzione a questa persona che ci ha interrotto. Possiamo quindi dedicare alcuni minuti al problema della scelta dello spettacolo teatrale (... non molti perché se no poi l'esame di Architettura chi lo supera!?!), senza per questo perdere definitivamente le informazioni che sono solo coperte dal giornale. Quando finalmente avremo deciso il da farsi per il teatro potremo congedare il nostro amico, pregarlo di portarsi via il suo giornale, e dedicarci nuovamente in santa pace al nostro compito primario.
Questo stesso modello di utilizzazione di tipo stack può essere realizzato per l'accesso alle celle di RAM da parte di un programma mediante la definizione di un opportuno registro nella CPU (comunemente chiamato FP - dalla abbreviazione di "frame pointer" - oppure BP - dalla abbreviazione di "base pointer") da utilizzarsi in abbinamento al modo di indirizzamento indicizzato. Supponiamo di identificare una zona di memoria RAM da dedicare alla realizzazione dello stack di sistema, per esempio le prime celle a partire dall'indirizzo 0 fino ad un certo valore opportunamente elevato in modo da garantire la disponibilita' di celle di memoria sufficenti per tutti i programmi che vogliamo eseguire. Ciascun programma farà uso di celle di memoria "contigue" in termini di indirizzo, che potranno essere visualizzate come "una fetta" della zona di RAM dedicata allo stack. Supponiamo che il programma P1 necessiti di 10 celle di RAM per memorizzare i suoi dati, e che il programma P2 ne richieda invece 15. Ebbene, P1 individuerà le sue 10 celle di RAM mediante l'indirizzamento indicizzato RAM[FP+0]. RAM[FP+1], ..., RAM[FP+9]; P2 dal canto suo individuerà le sue 15 celle di RAM mediante l'indirizzamento indicizzato RAM[FP+0]. RAM[FP+1], ..., RAM[FP+14]. Sarà compito del sistema operativo utilizzato su quella macchina convenzionale di assegnare preventivamente i valori corretti al registro FP per consentire a P1 di accedere ai suoi dati ed a P2 di accedere ai suoi dati.
Supponiamo ora che il nostro ipotetico programma P1 ad un certo punto della sua esecuzione richieda la sospensione di P1 e l'attivazione di P2 come estensione procedurale di P1 per realizzare una funzionalità complessa, non immediatamente riducibile alla esecuzione di una singola istruzione della macchina convenzionale. Al termine di P2 vorremo ovviamente che la macchina convenzionale riprenda l'esecuzione di P1 dal punto in cui era stata interrotta per consentire l'inizio della estensione procedurale P2. Dal punto di vista dell'accesso ai dati, questa sostituzione può essere realizzata sovrapponendo nello stack l'area dati di P2 a quella di P1. Nel nostro esempio tale sovrapposizione avviene sommando al valore precedentemente usato da P1 per FP la costante 10 per ottenere il valore di FP che dovra' essere usato da P2 (in modo che FP+0 calcolato da P2 si riduca allo stesso valore che sarebbe stato calcolato sommando 10 al valore di FP durante l'esecuzione di P1). Al fine di semplificare la sovrapposizione nello stack dell'area dati di un nuovo programma mandato in esecuzione in sostituzione di quello interrotto, normalmente viene introdotto un secondo registro nella CPU (chiamato SP, abbreviazione di "stack pointer") che delimita l'area dello stack usata dal programma in esecuzione, per esempio contenendo l'indirizzo della prima cella non usata subito dopo l'ultima cella usata dal programma.
Quindi per tornare al nostro esempio, il programma P1 potrebbe essere mandato in esecuzione dopo aver prefissato il valore 0 nel registro FP (in modo da allocare le sue 10 celle di memoria dedicate ai dati nelle prime celle disponibili nello stack). Il programma stesso potrebbe calcolarsi il valore da assegnare al registro SP sommando 10 al valore contenuto nel registro FP. In questo modo il programma potrebbe accedere ai suoi dati nel modo indicato in precedenza (RAM[FP+k], con k compreso tra 0 e 9), inidirizzando celle di RAM il cui indirizzo sarà sempre compreso tra il valore contenuto in FP (ossia 0) ed il valore contenuto in SP (ossia 10), quest'ultimo escluso. L'estensione procedurale potrebbe avvenire, dal punto di vista della sovrapposizione nello stack dei dati di P2, sostituendo al valore precedente di FP il valore precedente di SP, e poi sommando 15 al contenuto di SP (ottenendo quindi FP=10 ed SP=25 durante l'esecuzione di P2). Se P2 dovesse essere interrotto a sua volta per consentire l'esecuzione della estensione procedurale P3, la quale supponiamo richieda a sua volta 7 celle di memoria per la memorizzazione dei suoi dati, allora potremmo sovrapporre una nuova fetta di memoria nello stack assegnando ad FP il valore precedente di SP (ossia FP=25) e poi incrementando il valore di SP di 7 (ottenendo quindi SP=32 durante l'esecuzione di P3). Il programma P3 potrebbe quindi anche lui tranquillamente accedere ai suoi dati locali mediante l'indirizzamento indicizzato RAM[FP+0], ..., RAM[FP+6], senza interferire coi dati di P1 e P2 e senza minimamente essere condizionato dal fatto che P1 e P2 sono stati interrotti temporaneamente per consentire alla CPU di eseguire P3, ed automaticamente accedendo alle celle di memoria adiacenti nello stack a quelle usate da P1 e P2.
Questo semplice meccanismo di sovrapposizione della memoria nello stack richiede un piccolo "aggiustamento" per poter consentire anche l'operazione inversa di rimozione di uno strato dallo stack per ripristinare l'accesso corretto alle variabili di un programma precedentemente interrotto. Infatti, mentre il vecchio valore da riassegnare al registro SP si trova ancora memorizzato nel registro FP, il vecchio valore del registro FP sarebbe andato perso a seguito della sovrapposizione di una nuova fetta di memoria, e quindi non sarebbe più disponibile seguendo lo schema semplicistico delineato fin qua. La soluzione a questo problema può essere ottenuta in modo molto semplice copiando in una cella RAM il vecchio valore di FP prima che questo venga sostituito dal vecchio valore di SP durante l'attivazione della estensione procedurale. Ovviamente il posto più indicato per mantenere questo valore é una cella di RAM all'interno della struttura stack stessa. La procedura di sovrapposizione di una nuova fetta di memoria nello stack destinata a contenere i dati di un programma attivato come estensione procedurale di un altro precedentemente in esecuzione potrebbe quindi essere descritta dalla seguente sequenza di passi elementari:
RAM[SP] <- FP
FP <- SP
SP <- (SP +k +1)
dove "k" indica il numero di celle di RAM necessarie per contenere i dati
della procedura che si sta attivando.
Naturalmente ora (con questa nuova modalità di funzionamento),
il programma attivato potrà accedere alle sue celle di memoria
mediante l'insieme degli indirizzamenti indicizzati RAM[FP+1], ...,
RAM[FP+k].
L'operazione di eliminazione dallo stack della fetta di memoria
corrispondente ad una estensione procedurale conclusa (e quindi il
ripristino dell'esecuzione del programma precedentemente interrotto)
potrebbe essere ottenuta con la sequenza di passi elementari:
SP <- FP
FP <- RAM[SP]
Dovrebbe risultare evidente, a questo punto, che la tecnica di strutturazione a stack della memoria per i dati dei programmi appena delineata risolve in parte il problema di voler sospendere l'esecuzione di un programma temporaneamente, con l'idea di voler poi riprendere successivamente l'esecuzione dello stesso programma dal punto in cui lo avevamo lasciato. In particolare, questa struttura risolve direttamente il problema dei valori calcolati e memorizzati in celle di memoria, mentre non risolve direttamente il problema dei dati parziali calcolati e memorizzati nei registri della CPU. Per questi ultimi, se il programma che sostituisce quello interrotto usa gli stessi registri per calcolare altri dati, occorre provvedere ad un "salvataggio" in memoria RAM prima dell'attivazione della estensione procedurale, e ad un successivo "ripristino dei valori precedenti nei registri dopo la terminazione dell'estensione procedurale e prima del ripristino dell'esecuzione del programma interrotto. Tale salvataggio può ovviamente essere realizzato in ulteriori celle di memoria appositamente predisposte nello stack (così come abbiamo già visto nel caso del registro FP). Tra i valori dei registri da salvare per poter poi riprendere l'esecuzione del programma interrotto dallo stesso punto in cui era stato interrotto, sicuramente dobbiamo considerare il registro contatore di programma (PC). Tenendo conto di questa ulteriore necessità, le sequenze di passi elementari atte a realizzare le operazioni di attivazione e terminazione di una estensione procedurale (altrimenti dette "chiamata di" e "ritorno da procedura") potrebbero essere definite come segue.
Chiamata di procedura la cui prima istruzione si trova all'indirizzo i e che necessita di k celle nello stack per contenere i suoi dati:
RAM[SP] <- FP
FP <- SP
SP <- (SP +k +2)
RAM[FP+1] <- PC
PC <- i
Ritorno da procedura precedentemente attivata come sopra:
SP <- FP
FP <- RAM[SP]
PC <- RAM[SP+1]
Infine discutiamo una ultima estensione normalmente adottata dalle macchine convenzionali per rendere più conveniente la strutturazione a stack della parte di memoria dedicata ai dati. Spesso risulta conveniente strutturare un programma in modo da non dover allocare tutte le celle di memoria destinate a contenere dati fin dall'inizio. Sovente capita quindi che un programma in fase di esecuzione richieda l'uso di memoria non precedentemente allocata nella sua fetta di stack. L'aggiunta "dinamica" di nuove celle di memoria alla fetta di stack dedicata ad un programma P1 già in fase di esecuzione non comporta nessuna complicazione particolare, grazie all'uso di due registri di delimitazione: é sufficente infatti incrementare il valore contenuto nel registro SP (lasciando inalterato il valore contenuto nel registro FP) per "inspessire" la fetta di stack destinata a P1. Normalmente tutte le macchine convenzionali prevedono una istruzione chiamata PUSH che, usando il modo di indirizzamento auto-incremento, alloca una nuova cella nello stack e vi memorizza un valore. Analogamente una istruzione normalmente chiamata POP, sempre usando il modo di indirizzamento auto-incremento, legge il contenuto dell'ultima cella dello stack e la elimina (decrementando il valore contenuto nel registro SP).
Tutta la spiegazione impostata qui nel caso di stack che parte dalla cella 0 e cresce incrementando i valori dei registri SP ed FP potrebbe essere ripetuta utilizzando la convenzione opposta, ovvero facendo partire lo stack dall'ultima cella (quella di indirizzo più elevato e quindi facendo crescere lo stack decrementando i valori dei registri SP ed FP. L'esempio didattico di macchina convenzionale VM-2 userà proprio questa convenzione "rovesciata", e questa é anche la scelta della maggior parte delle macchine convenzionali effettivamente reperibili in commercio.
Nelle macchine convenzionali moderne sono stati concepiti ed utilizzati storicamente due modi diversi per consentire alla CPU di interagire con i dispositivi di controllo delle unità di ingresso e uscita dei dati: la definizione di istruzioni specificamente dedicate all'ingresso e uscita (istruzioni di I/O), oppure la tecnica di "proiezione in memoria" (memory mapping) dei registri delle unità di controllo.
La prima tecnica viene solitamente realizzata mediante l'introduzione di un bus separato (almeno da un punto di vista concettuale) per stabilire la comunicazione tra CPU e Controller rispetto al bus usato per stabilire la connessione tra CPU e memoria RAM. La CPU passa informazioni ad un controller mediante specifiche istruzioni (per esempio OUT nel caso delle architetture Intel x86) e raccoglie informazioni da un controller mediante altre specifiche istruzioni (per esempio IN nel caso delle architetture Intel x86). Il controller coinvolto nel trasferimento di informazioni viene individuato mediante la solita tecnica di indirizzamento binario, con l'unica differenza rispetto al caso dell'indirizzamento della RAM che, essendo il numero di controller connessi ad un sistema solitamente molto basso rispetto al numero di celle di memoria RAM, il numero di bit usati per la rappresentazione degli indirizzi su un bus di I/O é solitamente molto inferiore rispetto al numero di bit usati per la rappresentazione degli indirizzi su un bus di connessione con la memoria RAM.
Proprio l'osservazione della sostanziale analogia tra le operazioni di Input ed Output realizzate sul bus di I/O nella interazione tra CPU e controller e le operazioni di lettura e scrittura delle celle di memoria sul bus di connessione tra CPU e RAM ha portato ad una revisione della impostazione architetturale dei sistemi di concezione più moderna, mediante l'adozione della tecnica dei "memory mapped I/O registers". Notando che un controller assume sempre un comportamento di tipo passivo rispetto alla CPU, limitandosi a fornire informazioni quando la CPU le richiede e a eseguire "ordini" ricevuti sotto forma di codici binari provenienti dalla CPU, si può pensare di descriverne il comportamento in un modo molto simile a quello usato per descrivere il comportamento di un insieme di celle della memoria RAM. Quando la CPU vuole inviare delle informazioni o degli ordini da eseguire al controller può farlo fingendo di scrivere le informazioni in una o più celle di memoria RAM. Analogamente, quando la CPU vuole ottenere delle informazioni dal controller può farlo fingendo di leggere il contenuto di una o più celle di memoria RAM. Quindi a ciascun controller vengono assegnati un sottoinsieme degli indirizzi del bus, mentre alla memoria RAM vengono assegnati degli altri sottoinsiemi di indirizzi sullo stesso bus. La CPU interagirà con un controller nello stesso modo con cui interagisce normalmente con i moduli RAM, mediante normali istruzioni di lettura o scrittura del contenuto di una cella di memoria. L'unica differenza sarà, nel caso della interazione con un controller, che le informazioni non verranno memorizzate o estratte da una cella di memoria RAM ma trattate opportunamente dal dispositivo di controllo che viene attivato a seguito della decodifica dell'indirizzo.
La tecnica di "memory mapping" dei dispositivi é sia concettualmente
che praticamente più conveniente da realizzare e da utilizzare
rispetto a quella del "programmed I/O" separato e sta (lentamente, a causa
dei requisiti di "compatibilità" col software organizzato per
sistemi concepiti secondo i vecchi criteri) soppiantando quest'ultima.
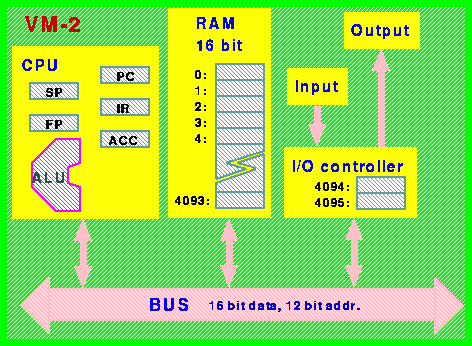
Passiamo ora a descrivere un esempio di macchina convenzionale inventata di sana pianta. Questa macchina ipotetica, che chiameremo con la sigla VM-2 (macchina virtuale di livello 2), non ha nessuna pretesa di rappresentare un esempio realistico di una architettura commerciale moderna come possono essere i vari Pentium, PowerPC, UltraSPARC, ecc. L'unico scopo di questo esempio é di fornire un punto di riferimento preciso e dettagliato per arrivare a comprendere in generale come può essere realizzata una macchina convenzionale, e come può essere programmata a livello di linguaggio macchina. La scelta di architetture più realistiche comporterebbe solo lo svantaggio di dover tener conto di una quantità di dettagli spaventosamente maggiore.
La struttura del sistema VM-2 é illustrata in figura:
Si compone di una unità centrale di elaborazione "a 16 bit", una unità di memoria organizzata in 4094 celle da 16 bit ciascuna, ed un controllore per i dispositivi di ingresso (tastiera) e uscita (video alfanumerico).
Il controllore delle unità di ingresso e uscita comunica con la CPU mediante l'uso di due registri "mappati" sugli indirizzi di memoria 4094 e 4095 (non utilizzati per indirizzare la RAM). Il registro associato all'indirizzo 4094 corrisponde al dispositivo di ingresso, mentre il registro associato all'indirizzo 4095 comanda il funzionamento del dispositivo di uscita. Entrambi i dispositivi utilizzano il codice ASCII su 7 bit per la rappresentazione dei caratteri. I 7 bit meno significativi dei due registri (anch'essi da 16 bit come tutte le "vere" celle di memoria) sono destinati a contenere la codifica ASCII dell'ultimo carattere letto o scritto.
Il bit più significativo dei due registri (ovvero il bit di segno, pensando ad una rappresentazione in complemento a 2) viene utilizzato per gestire un protocollo di comunicazione tra CPU e controller.
Nel caso del registro di indirizzo 4094, il bit di segno viene posto al valore 0 dal controller quando l'utente ha digitato un tasto, e la codifica ASCII del carattere digitato é contenuta nei 7 bit meno significativi. Altrimenti, quando l'utente non ha digitato alcun carattere, il bit di segno viene mantenuto al valore 1 dal controller. Quando la CPU effettua un accesso in lettura alla locazione 4094, il controller riconosce il fatto che la CPU ha "consumato" la codifica ASCII del carattere contenuta nel registro, e riporta quindi il bit di segno al valore 1. Se la CPU non consuma la codifica ASCII di un carattere prima che l'utente digiti un altro carattere, l'informazione riguardante il carattere precedente viene persa, e la sua codifica ASCII viene ricoperta da quella dell'ultimo carattere digitato.
Nel caso del registro di indirizzo 4095, il bit di segno può essere posto al valore 0 dalla CPU mediante un accesso in scrittura. In tal caso il controller mantiene il bit di segno al valore 0 per tutto il tempo necessario a stampare sul dispositivo di uscita il carattere identificato dalla codifica ASCII contenuta nei 7 bit meno significativi del registro. Al termine della operazione di stampa il controller riporta il bit di segno al valore 1. Se la CPU effettua un accesso in scrittura all'indirizzo 4095 prima che sia terminata la stampa di un carattere (ossia mentre il bit di segno assume il valore 0), tale stampa in corso viene abortita.
Per quanto riguarda la CPU, questa contiene un registro ACC (accumulatore), un registro IR (instruction register) ed un'ALU da 16 bit. I rimanenti registri chiamati PC (program counter), SP (stack pointer) e FP (frame pointer) sono invece da 12 bit, essendo destinati a contenere indirizzi di celle di memoria compresi tra 0 e 4095.
Per consentire la sperimentazione di programmi su questa macchina si suppone di avere la possibilità di introdurre "magicamente" dall'esterno insiemi di valori predefiniti nelle celle di memoria senza far ricorso ad un programma di bootstrap (funzionalità di questo tipo vengono di solito fornite per i cosiddetti sistemi di sviluppo di applicazioni per microprocessori, e sono ottenute mediante l'uso di CPU, dischi e memorie ausiliarie rispetto al sistema "target", oppure per i simulatori di sistemi non fisicamente realizzati).
Le istruzioni della macchina VM-2 vengono tutte codificate su 16 bit, in modo da poter utilizzare una singola cella di memoria per contenere la rappresentazione di una istruzione. Viene utilizzata una tecnica di espansione del codice operativo delle istruzioni per lasciar spazio ad operandi specificati su 8 oppure 12 bit (a seconda dell'istruzione).
L'insieme delle istruzioni con la loro codifica binaria e la loro semantica
é riassunto nella seguente tabella (dove i simboli
AAAAAAAAAAAA, ecc. rappresentano una qualunque configurazione
di bit - tanti bit quante sono le ripetizioni della lettera, M[X]
rappresenta il contenuto della cella di RAM di indirizzo X, ed il nome dei
registri rappresenta il valore in esso contenuti):
0000AAAAAAAAAAAA
IF (ACC >= 0) THEN PC <-- AAAAAAAAAAAA
0001AAAAAAAAAAAA
IF (ACC < 0) THEN PC <-- AAAAAAAAAAAA
0010AAAAAAAAAAAA
IF (ACC = 0) THEN PC <-- AAAAAAAAAAAA
0011AAAAAAAAAAAA
IF (ACC <> 0) THEN PC <-- AAAAAAAAAAAA
0100AAAAAAAAAAAA
ACC <-- M[AAAAAAAAAAAA]
0101AAAAAAAAAAAA
ACC <-- ACC + M[AAAAAAAAAAAA]
0110AAAAAAAAAAAA
ACC <-- ACC AND M[AAAAAAAAAAAA]
0111AAAAAAAAAAAA
M[AAAAAAAAAAAA] <-- ACC
1000AAAAAAAAAAAA
ACC <-- M[FP + AAAAAAAAAAAA]
1001AAAAAAAAAAAA
ACC <-- ACC + M[FP + AAAAAAAAAAAA]
1010AAAAAAAAAAAA
ACC <-- ACC AND M[FP + AAAAAAAAAAAA]
1011AAAAAAAAAAAA
M[FP + AAAAAAAAAAAA] <-- ACC
1100AAAAAAAAAAAA
PC <-- AAAAAAAAAAAA
1101AAAAAAAAAAAA
ACC <-- M[ACC + AAAAAAAAAAAA]
1110AAAAAAAAAAAA
M[SP] <-- FP; FP <-- SP; SP <-- (SP - 1); M[SP] <-- PC; SP <-- (SP - 1); PC <-- AAAAAAAAAAAA
11110000CCCCCCCC
ACC <-- 00000000CCCCCCCC
11110001CCCCCCCC
ACC <-- CCCCCCCC00000000 OR (ACC AND 0000000011111111)
11110010CCCCCCCC
SP <-- SP + 0000CCCCCCCC
11110011CCCCCCCC
SP <-- SP - 0000CCCCCCCC
11110100XXXXXXXX
M[SP] <-- ACC; SP <-- (SP - 1);
11110101XXXXXXXX
M[SP] <-- M[ACC]; SP <-- (SP - 1);
11110110XXXXXXXX
SP <-- (SP + 1); ACC <-- M[SP];
11110111XXXXXXXX
SP <-- (SP + 1); M[ACC] <-- M[SP];
11111000XXXXXXXX
tmp <-- ACC; ACC <-- 0000(SP); SP <-- tmp;
11111001XXXXXXXX
tmp <-- ACC; ACC <-- 0000(FP); FP <-- tmp;
11111010XXXXXXXX
ACC <-- NOT ACC
11111011XXXXXXXX
ACC <-- (-ACC)
11111100XXXXXXXX
SP <-- FP; PC <-- M[FP-1]; FP <-- M[FP]
11111101XXXXXXXX
11111110XXXXXXXX
ACC <-- (ACC>>1)
11111111XXXXXXXX
ACC <-- (ACC<<1)
Cominciamo a considerare un semplice esempio di programma per la
lettura dal dispositivo di ingresso.
In particolare definiamo una procedura che attenda l'inserimento
di un carattere di tipo numerico e ne ritorni il valore decodificato
(compreso tra 0 e 9) nel registro accumulatore.
In caso di errore la procedura ritorna un valore negativo nel
registro accumulatore.
100: 1111000000110000 (LOC8 48, carattere 0 in codice ASCII)
101: 1111101100000000 (SIGN)
102: 1111010000000000 (PUSH)
103: 0100111111111110 (LODD 4094)
104: 0001000001100111 (JNEG 103)
105: 1001111111111110 (ADDL -2)
106: 0000000001101100 (JPOS 108)
107: 1111110000000000 (RETN)
108: 1011111111111110 (STOL -2)
109: 1111101100000000 (SIGN)
110: 1111010000000000 (PUSH)
111: 1111000000001001 (LOC8 9)
112: 1001111111111101 (ADDL -3)
113: 0001000001101011 (JNEG 107)
114: 1000111111111110 (LODL -2)
115: 1111110000000000 (RETN)
Analogamente possiamo definire una procedura destinata a stampare
un carattere numerico sul dispositivo di uscita, dato un valore
compreso tra 0 e 9 nel registro accumulatore:
116: 0000000001110110 (JPOS 118)
117: 1111110000000000 (RETN)
118: 1111010000000000 (PUSH)
119: 1111101100000000 (SIGN)
120: 1111010000000000 (PUSH)
121: 1111000000001001 (LOC8 9)
122: 1001111111111101 (ADDL -3)
123: 0001000001110101 (JNEG 117)
124: 0100111111111111 (LODD 4095)
125: 0000000001111100 (JPOS 124)
126: 1111000000110000 (LOC8 48)
127: 1001111111111110 (ADDL -2)
128: 0111111111111111 (STOD 4095)
129: 1111110000000000 (RETN)
Alla fine della procedura, se il registro accumulatore contiene un valore
negativo allora si é verificato un errore che ha impedito la stampa,
altrimenti il carattere é stato stampato.
Notare la coppia di istruzioni LODD e salto condizionale all'indietro (indirizzi 103, 104 per la prima procedura e indirizzi 124, 125 per la seconda procedura). Tale struttura di programma viene chiamata busy waiting, e consente alla CPU di aspettare che il dispositivo di I/O sia pronto per portare a termine l'operazione.
Volendo organizzare un programma che legga due cifre numeriche dalla tastiera
e stampi sul video il risultato della loro somma, segnalando eventualmente
condizioni di errore, si potrebbero usare le due procedure sopra descritte
come segue:
0: 1111000011111101 (LOC8 253)
1: 1111000100001111 (LOCH 3840)
2: 1111100000000000 (SWAS)
3: 1111000011111111 (LOC8 255)
4: 1111000100001111 (LOCH 3840)
5: 1111100100000000 (SWAF)
6: 1110000001100100 (CALL 100)
7: 0000000000001101 (JPOS 13)
8: 0100111111111111 (LODD 4095)
9: 0000000000001000 (JPOS 8)
10: 1111000001000101 (LOC8 69, carattere E in ASCII)
11: 0111111111111111 (STOD 4095)
12: 1111110100000000 (HALT)
13: 1111010000000000 (PUSH)
14: 1110000001100100 (CALL 100)
15: 0001000000001000 (JNEG 8)
16: 1001111111111110 (ADDL -2)
17: 1110000001110100 (CALL 116)
18: 0001000000001000 (JNEG 8)
19: 1111110100000000 (HALT)
Notare la parte di inizializzazione dei valori per i registri SP ed FP, l'uso
dell'istruzione HALT per la terminazione del programma e l'uso del registro
ACC per passare valori tra programma principale e procedura, e viceversa.
Passiamo ora ad un esempio di procedure di I/O più complesse: la lettura
e scrittura di valori numerici usando la notazione ottale.
Proviamo quindi a modificare la procedura di lettura di un valore pensando
che questo possa essere rappresentato dall'utente digitando una sequenza di
caratteri di tipo numerico (ciascuno compreso tra "0" e "7");
considereremo qualsiasi carattere diverso dalle cifre ottali come terminatore
di una stringa di caratteri che identifica un numero.
D'ora in avanti useremo solo la forma simbolica per la rappresentazione delle
istruzioni, dando per scontato che questa é solo una abbreviazione per
la rappresentazione binaria che deve essere inserita in RAM.
La versione modificata della procedura potrebbe quindi essere:
100: LOC8 48 (carattere 0 in codice ASCII)
101: SIGN
102: PUSH
103: LOC8 8
104: SIGN
105: PUSH
106: LOC8 0
107: PUSH
108: LODD 4094
109: JNEG 108
110: ADDL -2
111: JPOS 114
112: LODL -4
113: RETN
114: PUSH
115: (ADDL -3)
116: JPOS 112
117: LODL -4
118: LSHF
119: LSHF
120: LSHF
121: ADDL -5
122: STOL -4
123: INSP 1
124: JUMP 108
Notare che in questa versione modificata non vengono mai segnalate condizioni di errore:
la ricezione anche di un singolo carattere non ottale viene semplicemente interpretato
come la terminazione di un numero (che per default assume il valore zero).
Notare anche che non viene trattata esplicitamente nessuna condizione di overflow:
se l'utente digita troppe cifre ottali, vengono semplicemente caricati gli ultimi
16 bit (quelli meno significativi) nel registro accumulatore.
Vediamo ora una versione ricorsiva per la realizzazione della
procedura di stampa in codice ottale:
125: PUSH
126: LOC8 48 (carattere 0 in codice ASCII)
127: PUSH
128: LODL -2
129: JNZE 136
130: LODD 4095
131: JPOS 130
132: LODL -2
133: ADDL -3
134: STOD 4095
135: RETN
136: RSHF
137: RSHF
138: RSHF
139: JZER 141
140: CALL 125
141: LOC8 7
142: ANDL -2
143: STOL -2
144: JUMP 130
Anche in questo caso non sono previste segnalazioni di errore:
la stampa va sempre a buon fine, utilizzando un numero di caratteri
variabile a seconda del valore da stampare.
La versione modificata del programma principale per leggere due
valori e stampare il risultato della somma in ottale sarà:
0: LOC8 253
1: LOCH 3840
2: SWAS
3: LOC8 255
4: LOCH 3840
5: SWAF
6: CALL 100
7: PUSH
8: CALL 100
9: ADDL -2
10: CALL 125
11: HALT
Una versione un po' meno scarna di programma potrebbe includere l'eco
dei valori letti sul dispositivo di uscita:
0: LOC8 253
1: LOCH 3840
2: SWAS
3: LOC8 255
4: LOCH 3840
5: SWAF
6: CALL 100
7: PUSH
8: CALL 125
9: LOC8 43 (carattere + in codice ASCII)
10: PUSH
11: CALL 25
12: CALL 100
13: STOL -3
14: CALL 125
15: LOC8 61 (carattere = in codice ASCII)
16: PUSH
17: CALL 25
18: LODL -3
19: ADDL -2
20: CALL 125
21: LOC8 10 (carattere New Line in codice ASCII)
22: STOL -4
23: CALL 25
24: HALT
25: LODD 4095
26: JPOS 25
27: LODL 1
28: STOD 4095
29: RETN
Notare l'uso dello stack per il passaggio del valore corrispondente alla codifica
ASCII di un carattere da stampare alla procedura di stampa di carattere che inizia
all'indirizzo 25.
La procedura accede a questa informazione mediante uno spiazzamento positivo
rispetto al valore del registro FP, assumendo che il parametro sia
memorizzato sul top dello stack precedente alla chiamata della procedura stessa.