|
|
|
|
|
|
| La classe HashSet
fornisce una realizzazione dell'interfaccia Set utilizzando
tabelle hash con la strategia di concatenamento per la risoluzione delle
collisioni.
Per il calcolo del codice hash degli oggetti da memorizzare,
si sfrutta il metodo
public int hashCode() definito nella
classe Object, e quindi invocabile su qualunque oggetto
Java.
L'intero restituito dal metodo hashCode() viene quindi trasformato eseguendo un'operazione di modulo rispetto alla lunghezza dell'array.
|
|
|
|
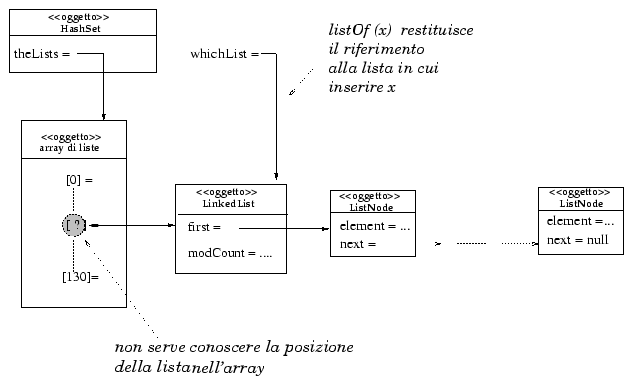
La classe HashSet
ha due variabili d'istanza:
|
|
|
|
Il metodo ausiliario listOf restituisce
la lista designata a contenere un dato oggetto x. L'indice
di tale lista viene determinato normalizzando il valore hash dell'oggetto
(x.hashCode()) rispetto alla lunghezza dell'array, e trasformandolo
in positivo se necessario.
|
|
|
|
Utilizzando il metodo ausiliario listOf,
i metodi add, remove e contains
si riducono di fatto ad operare in modo opportuno sulla lista ottenuta.
|
|
|
|
Il metodo isEmpty deve restituire
true
se tutte le liste della tabelle sono vuote, false altrimenti.
Il metodo clear rende vuote tutte le liste nella tabella.
Il metodo iterator restituisce un iteratore per scandire gli oggetti dell'insieme.
|
|
|
|
| Denotando con È possibile migliorare il codice rendendo la tabella
dinamica in maniera analoga a quanto fatto con le realizzazioni tramite
array di pile e code. Quando il fattore di carico Nel caso ci siano problemi di occupazione di memoria, è opportuno adottare una strategia di risoluzione delle collisioni basata sul metodo di indirizzamento aperto, che non usa liste. |
|
|
|
| I seguenti sono metodi ausiliari per la primalità.
Il metodo
primes(int n) restituisce un array di booleani
lungo
n che vale true nelle posizioni corrispondenti ai
numeri primi; il metodo nextPrime(int n) restituisce il
più piccolo numero primo maggiore di n.
Il metodo nextPrime(int n) si basa sul risultato [Bertrand, Chebyshev] seguente: per n > 1 esiste un numero primo compreso tra n e 2n. nextPrime(int n) invoca primes(2*n) sicuro che il prossimo primo sarà trovato tra n e 2n. Il metodo primes(int n) realizza il crivello
di Eratostene, elencando tutti i numeri primi minori di un numero dato
in ingresso. L'idea è semplice: dato un numero primo, tutti i suoi
multipli non sono primi. Consideriamo un insieme, che inizialmente contiene
tutti i numeri maggiori o uguali a due. Ogni volta che individuiamo un
numero primo, escludiamo dall'insieme tutti i suoi multipli. Più
precisamente, cominciamo con l'escludere dall'insieme i multipli di 2,
poi quelli di 3, poi quelli di 5 (4 non viene considerato in quanto già
escluso come multiplo di 2), e così via.
|
|
|
|
Descriviamo ora la realizzazione degli iteratori
su tabelle hash fornita dalla classe interna
ProtectedItr.
Una istanza di ProtectedItr visita gli elementi dell'insieme
scandendo tutte le liste della tabella hash a partire da quella di posizione
0. Le variabili d'istanza sono:
|
|
|
|
Il metodo ausiliario nextList()
assegna a tableCursor l'indice della prossima lista non
vuota, se esiste, oppure theLists.length se non esiste.
Il costruttore cerca la prima lista non vuota e costruisce
un iteratore su tale lista assegnandolo a listCursor. Se
tutte le liste sono vuote (la tabella è vuota) a listCursor
viene assegnato null.
|
|
|
|
Il metodo hasNext() restituisce
true
(indicando che c'è un altro oggetto da visitare) se la lista che
si sta visitando con listCursor non è finita, oppure
se è finita ed esiste un'altra lista non vuota da visitare.
Il metodo next() restituisce il prossimo
oggetto da visitare nell'iterazione, se esiste. Se la lista che si
sta visitando con listCursor non è finita, se ne
restituisce il prossimo elemento. Altrimenti si crea un iteratore sulla
prossima lista non vuota, e se ne restituisce il primo elemento dopo aver
aggiornato il valore di tableCursor con nextList().
Il metodo remove() cancella l'oggetto
restituito dall'ultima chiamata al metodo next(), richiamando
remove()
sull'iteratore della lista corrente.
|
|
|
|
|
1) Scrivere la classe ListSet che realizza gli insiemi usando le liste concatenate.
2) Scrivere la classe VectorSet che realizza gli insiemi usando Vector.
3) Si definisca l'interfaccia RichSet, che estende Set aggiungendo i metodi elencati di seguito. Si fornisca quindi un'implementazione dell'interfaccia RichSet estendendo la classe ListSet, VectorSet, oppureHashSet. Definire infine una classe TestRichSet per testare i nuovi metodi.
|