|
|
|
|
|
|
|
Vedremo due realizzazioni del tipo di dati astratto Insieme:
|
|
|
|
|
Le tabelle hash sono strutture dati che permettono di memorizzare arbitrari insiemi di oggetti, fornendo un accesso molto efficiente agli elementi memorizzati. Supportano un insieme ristretto di metodi, quali inserzione, ricerca, cancellazione. Godono delle seguenti proprietà:
|
|
|
|
| Supponiamo di voler memorizzare degli oggetti
in una tabella di dimensione n (cioè con n posizioni,
comprese tra 0 e n-1). La memorizzazione degli oggetti avviene assegnando
ad ogni oggetto un numero intero i, detto codice hash, tra
0 e n-1 e posizionando l'oggetto nell'i-esima posizione della
tabella. La ricerca di un oggetto avviene calcolando il suo codice hash
e quindi accedendo alla corrispondente posizione della tabella.
La realizzazione più comune delle tabelle hash si basa sull'uso di array:
|
|
|
|
Se gli elementi da memorizzare nella tabella hash
sono interi, una semplice di funzione hash è data dall'operatore
modulo con la dimensione della tabella come secondo argomento:
Per le stringhe, si può usare la seguente:
Il calcolo della funzione hash suddetta trasforma una
stringa L'intero restituito dal metodo hash viene quindi convertito eseguendo un'operazione di modulo rispetto alle dimensioni della tabella. Se negativo (ciò può accadere a causa del trabocco generato dal metodo hash), il risultato del modulo viene trasformato (traslato) in positivo:
|
|
|
|
| Fissate la dimensione della tabella e la funzione
hash, c'è una collisione se applicando la funzione a due
oggetti diversi e normalizzando i risultati rispetto alla dimensione
della tabella (con l'operazione di modulo) si ottiene lo stesso valore.
Per ridurre la frequenza di collisioni è utile usare tabelle con un numero primo di posizioni. Le collisioni sono inevitabili se la cardinalità dell'insieme che si vuole memorizzare è maggiore della dimensione della tabella. Ad esempio, se vogliamo memorizzare gli interi nell'itervallo [1, 14] in una tabella di dimensione 11, usando la funzione hash che calcola il modulo, abbiamo:
Nel seguito indicheremo con hash'(x) il risultato di hash(x) normalizzato alla dimensione della tabella. |
|
|
|
| In caso di collisioni, una tabella hash non può
essere utilizzata nel modo descritto sopra: se x e y
sono due oggetti diversi e hash'(x) = hash'(y), non possiamo memorizzarli
entrambi nella stessa posizione della tabella.
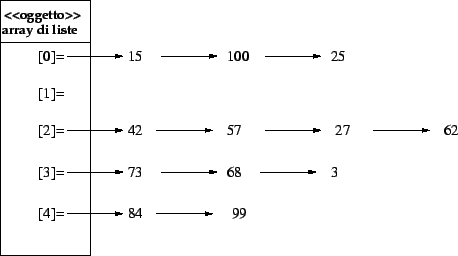
Esistono diverse strategie di risoluzione delle collisioni. Nella strategia di concatenamento, la tabella è realizzata con un array di liste o catene (chain), nelle quali vengono inseriti gli oggetti. Quindi un oggetto x sarà contenuto nella lista che si trova in posizione hash'(x), insieme a tutti gli oggetti in collisione con esso. Ad esempio, supponiamo di voler inserire, nell'ordine,
gli interi: 42, 15, 100, 25, 73, 68, 84, 57, 3, 99, 27, 62 in una tabella
realizzata con un array di lunghezza 5. Assumendo che la funzione hash
riduca gli interi dati modulo 5, la tabella risulta essere la seguente.
Per ridurre la frequenza di collisioni, occorre che la
dimensione della tabella tableSize sia sufficientemente
grande rispetto al numero n di oggetti da memorizzare, in modo che
la lunghezza media delle liste ( |