Il progetto consiste nel realizzare un'interfaccia grafica per un'applicazione di compressione di immagini.
Un'immagine consiste in una matrice di pixel, ciascuno dei quali contiene tre valori di colore rosso, verde, blu.
Supponiamo che ognuno dei colori sia rappresentato su 8 bit (questo equivale a 128 gradazioni di rosso, 128 di verde, 128 di blu) e che l'immagine abbia larghezza W (per semplicita' consideriamo immagini quadrate).
In questo caso la quantita' di bit richiesta e' pari a W*W*3*8.
Per esempio se W=1024 l'immagine occupa 24 Mb.
Se, quando un'immagine e' visualizzata, necessariamente ogni suo pixel deve essere in memoria, viceversa non e' strettamente necessario che il file contenente un'immagine contenga separatamente i colori per tutti i singoli pixel.
Notiamo che spesso nelle immagini vaste aree hanno lo stesso colore, o colori molto simili (indistinguibili a occhio).
Quindi un metodo di compressione raggruppa pixel contigui aventi (quasi) lo stesso colore in un solo "macro-pixel", per il quale memorizza l'informazione di colore una sola volta. In questo modo si ottengono file piu' piccoli.
Il metodo di compressione usa una soglia di tolleranza per decidere quando due colori sono "abbastanza simili" per accorparli. Questa soglia determina la perdita di precisione tollerata.
Si noti che anche quando la soglia di tolleranza sia zero, si potrebbe avere risparmio di spazio (vengono comunque compressi i pixel contigui aventi esattamente lo stesso colore).
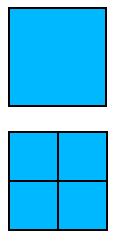
Nel caso specifico il nostro metodo di compressione utilizza un raggruppamento dei pixel a gruppi di quattro.
Per comodita', e' piu' facile spiegare il funzionamento "al contrario", partendo da un'immagine che supponiamo collassata in un solo macro-pixel, e definendo fino a che punto e' necessario espandere questo macro-pixel.
Assumiamo che la larghezza W dell'immagine sia una potenza di due.
Supponiamo di avere l'immagine di partenza e l'immagine compressa. Questa seconda e' inizialmente costituita da un solo macro-pixel grande quanto l'immagine e il cui colore e' uguale alla media aritmetica (calcolata separatamente per i tre colori rosso, verde, blu) dei colori di tutti i pixel dell'immagine originaria.
Se la massima differenza tra questo colore unico e il colore di ciascun pixel dell'immagine originale e' minore della soglia, allora questa e' esattamente la nostra versione compressa dell'immagine di partenza.
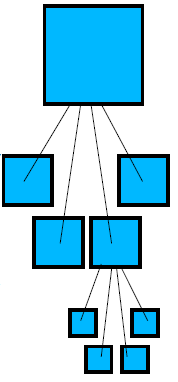
Altrimenti, dividiamo il macro-pixel in quattro quadranti, che diventano i nuovi candidati macro-pixel per l'immagine compressa. Il colore di ciascuno di essi e' posto uguale alla media aritmetica dei colori dei pixel nel quarto di immagine di partenza corrispondente.
Riapplichiamo lo stesso ragionamento a ciascuno dei quattro macro-pixel per vedere se e' "accettabile" in base alla soglia di tolleranza. Se lo e', va a far parte dell'immagine compressa finale. Altrimenti, viene a sua volta suddiviso in quattro quadranti... Il processo continua fino a che o il macro-pixel corrente rispetta la soglia di tolleranza, oppure non e' piu' "macro" in quanto coincide con un singolo pixel. In questo caso ovviamente non si suddivide piu' e il pixel va a far parte dell'immagine compressa.
Vedere figura illustrativa
Nel caso piu' semplice, la soglia di tolleranza consiste nella massima differenza di colore accettabile tra un macro-pixel e i pixel che esso "ricopre", espressa con tre valori distinti per rosso, verde, blu.
Si noti che la terna (0,0,0) corrisponde ad una compressione senza perdita di precisione rispetto all'immagine originale.
Vedere figure di esempi
E' altresi' possibile specificare due tolleranze differenti che devono essere applicate, rispettivamente, dentro e fuori una "zona di interesse" dell'immagine.
Supponiamo che l'immagine ritragga una persona su uno sfondo. E' ragionevole che sulla parte di immagine contenente la persona si tolleri poca o nessuna perdita di precisione, mentre per lo sfondo si ammetta una perdita di precisione anche alta.
Questo si ottiene specificando come "zona di interesse" un poligono che racchiude la sagoma della persona e definendo valori opportuni per le due tolleranze "dentro" e "fuori".
Vedere figure di esempi
Si distinguono due fasi:
Figura della suddivisione di un macro-pixel e della stessa vista come
albero:
Piu' precisamente l'applicazione permette di:
Vi sara' fornito un insieme di classi java che implementeranno queste funzionalita', e che voi dovrete usare a scatola chiusa, senza modificarle.