1.3) Aspetti software delle reti |
Le prime reti furono progettate cominciando
dall'hardware e sviluppando il software solo successivamente,
quasi come se esso fosse un'accessoria appendice dell'hardware.
Questo approccio non funziona più. Il SW di rete è
oggi altamente strutturato. Esaminiamo ora, a grandi linee, tale
strutturazione, che servirà da guida per l'intero corso
e sulla quale torneremo spesso.
1.3.1) Gerarchie di protocollo |
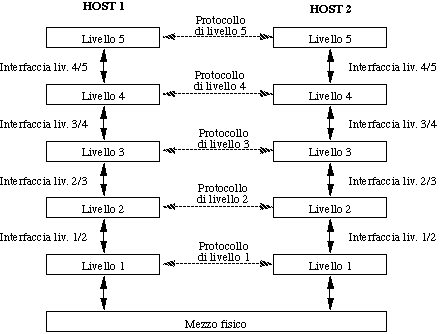
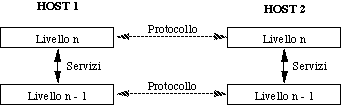
Per ridurre la complessità di progetto, le reti sono in generale organizzate a livelli, ciascuno costruito sopra il precedente. Fra un tipo di rete ed un altra, possono essere diversi:
Comunque un principio generale è sempre rispettato:
Il livello n su un host porta avanti una conversazione col livello
n su di un'altro host. Le regole e le convenzioni che governano
la conversazione sono collettivamente indicate col termine di
protocollo di livello n.
Le entità (processi) che effettuano tale conversazione
si chiamano peer entitiy (entità
di pari livello).
Il dialogo fra due peer entity di livello n viene materialmente
realizzato tramite i servizi offerti dal livello (n-1).
Fra ogni coppia di livelli adiacenti è definita una interfaccia, che caratterizza:
I vantaggi di una buona progettazione delle interfacce sono:
1.3.2) Architettura di rete |
L'insieme dei livelli e dei relativi protocolli
è detto architettura di rete.
La specifica dell' architettura deve essere abbastanza dettagliata
da consentire la realizzazione di SW e/o HW che, per ogni livello,
rispetti il relativo protocollo.
Viceversa, i dettagli implementativi di ogni livello e le interfacce
fra livelli non sono parte dell'architettura, in quanto sono nascosti
all'interno di un singolo host.
E' quindi possibile che sui vari host della rete ci siano implementazioni
che differiscono fra di loro anche in termini di interfacce fra
livelli, purché ogni host implementi correttamente i protocolli
previsti dall'architettura. In questo caso possono dialogare fra
loro anche host aventi caratteristiche (processore, sistema operativo,
costruttore) diverse.
Dunque, nell'ambito di una specifica architettura di rete, si ha che:
Un'architettura di rete può essere:
Un'architettura proprietaria è basata su scelte indipendenti
ed arbitrarie del costruttore, ed è generalmente incompatibile
con architetture diverse. Nel senso più stretto del termine
è un'architettura per la quale il costruttore non rende
pubbliche le specifiche, per cui nessun altro può produrre
apparati compatibili.
Esempi:
Un'architettura standard de facto è un'architettura basata
su specifiche di pubblico dominio (per cui diversi costruttori
possono proporre la propria implementazione) che ha conosciuto
una larghissima diffusione.
Esempi:
Un'architettura standard de iure è un'architettura basata
su specifiche (ovviamente di pubblico dominio) approvate da enti
internazionali che si occupano di standardizzazione. Anche in
questo caso ogni costruttore può proporne una propria implementazione.
Esempi:
L'insieme dei protocolli utilizzati su un host e relativi ad una
specifica architettura di rete va sotto il nome di pila
di protocolli (protocol stack). Si noti che un
host può avere contemporaneamente attive più pile
di protocolli.
1.3.3) Funzionamento del software di rete |
Per comprendere i meccanismi basilari di funzionamento
del software di rete si può pensare alla seguente analogia
umana, nella quale un filosofo indiano vuole conversare con uno
stregone africano:
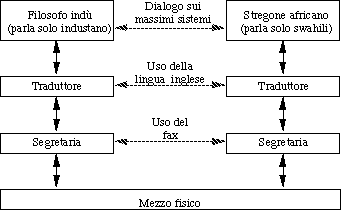
Nel caso delle reti, la comunicazione fra le due entità
di livello superiore avviene con una modalità che, almeno
in linea di principio, è uguale in tutte le architetture
di rete:
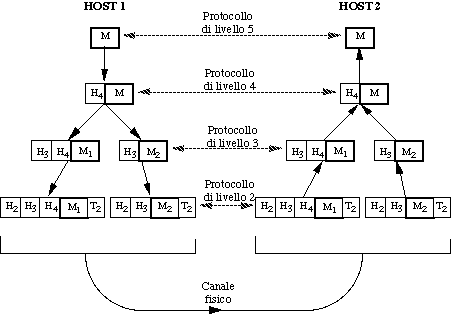
Vediamo cosa accade:
Aspetti importanti sono i seguenti:
1.3.4) Interfacce e servizi |
La funzione di ogni livello è di offrire
servizi al livello superiore. Il livello inferiore è il
service provider, quello
superiore è il service user.
Un livello n che usufruisce dei servizi di livello (n-1) può,
per mezzo di questi, a sua volta offrire al livello (n+1) i propri
servizi.
I servizi sono disponibili ai SAP (Service
Access Point). I SAP del livello n, o n-SAP,
sono i punti di accesso nei quali il livello (n+1) può
accedere ai servizi del livello n. Ogni n-SAP ha un indirizzo
che lo identifica univocamente.
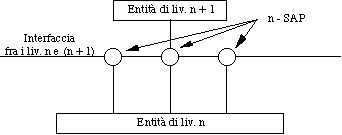
Analogia col telefono:
L'informazione passata dal livello n al livello (n-1), attraverso
il (n-1)-SAP, si dice PDU (Protocol
Data Unit) di livello n, o n-PDU.
Essa, entrando nel livello (n-1), diventa una SDU
(Service Data Unit) di livello (n-1), o (n-1)-SDU.
Entro il livello (n-1) viene aggiunta alla (n-1)-SDU una PCI
(Protocol Control Information) di livello (n-1).
Il tutto diventa una (n-1)-PDU, che verrà passata al livello
(n-2) attraverso un (n-2)-SAP.
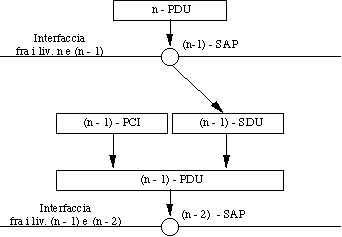
Nomi spesso usati per i PDU:
Nome per il PCI:
1.3.5) Servizi connection-oriented e connectionless |
Ci sono due principali classi di servizi offerti da un livello a quello superiore:
Servizi connection-oriented
I servizi connection-oriented sono modellati secondo il sistema telefonico, dove per parlare con qualcuno si alza il telefono, si chiama, si parla e poi si riattacca. Ovvero:
Analogamente, un servizio connection-oriented si sviluppa in 3 fasi:
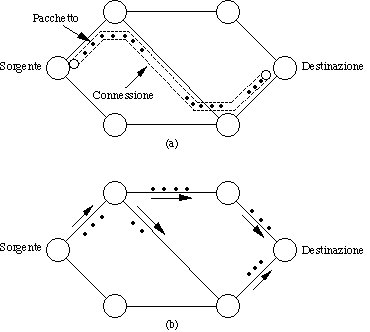
Servizi connectionless
I servizi connectionless sono modellati secondo il sistema postale:
ogni lettera viaggia indipendentemente dalle altre; arriva quando
arriva, e forse non arriva. Inoltre, due lettere con uguale mittente
e destinatario possono viaggiare per strade diverse.
Analogamente, in un servizio connectionless, i pacchetti (PDU)
viaggiano indipendentemente gli uni dagli altri, possono prendere
strade diverse ed arrivare in ordine diverso da quello di partenza
o non arrivare affatto.
La fase è una sola:
1.3.6) Affidabilità del servizio |
Un servizio è generalmente caratterizzato
dall'essere o no affidabile
(reliable).
Un servizio affidabile
non perde mai dati, cioé assicura che tutti i dati spediti
verranno consegnati al destinatario. Ciò generalmente richiede
che il ricevente invii un acknowledgement
(conferma) alla sorgente per ogni pacchetto ricevuto.
Si introduce ovviamente overhead, che in certe situazioni può
non essere desiderabile.
Viceversa, un servizio non affidabile
non offre la certezza che i dati spediti arrivino effettivamente
a destinazione.
Si noti che se un certo livello non offre nessun servizio affidabile,
qualora tale funzionalità sia desiderata dovrà essere
fornita da almeno uno dei livelli superiori (vedremo che ciò
accade spesso).
Esempi:
1.3.7) Primitive di definizione del servizio |
Un servizio di livello n è formalmente specificato da un insieme di primitive (cioé operazioni) che un'entità di livello (n+1) può adoperare per accedere al servizio. Esse possono indicare al servizio:
Un esempio di primitive può essere il seguente:
request() |
|
indication() |
|
response() |
|
confirm() |
Per stabilire una connessione fra le peer entity A a B si avrà
che:
connect.request() |
| ||
connect.indication() |
| ||
connect.response() |
| ||
connect.confirm() |
|
Le primitive hanno vari parametri (mittente, destinatario, tipo
del servizio richiesto, ecc.), che possono essere usati dalle
peer entity per negoziare le caratteristiche della connessione.
I dettagli della negoziazione fanno parte del protocollo.
Ad esempio, un servizio può essere richiesto in modalità
confermata oppure non confermato.
Per il servizio confermato avremo:
request();
indication();
response();
confirm().
Mentre per il servizio non confermato:
request();
indication().
Connect è sempre confermato (ovviamente), ma altri servizi
no.
Vediamo ora un esempio di servizio connection oriented con 8 primitive:
connect.request();
connect.indication();
connect.response();
connect.confirm();
data.request(): si cerca di inviare dati;
data.indication(): sono arrivati dei dati;
disconnect.request(): si vuole terminare la connessione;
disconnect.indication(): l'altra entity vuole
terminare.
La sequenza di primitive che entrano in gioco successivamente
nel corso della gestione di una connessione è la seguente:
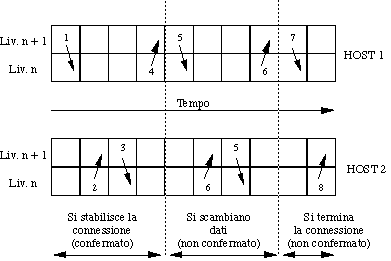
1.3.8) Servizi vs. protocolli |
Servizi e protocolli sono spesso confusi,
ma sono concetti ben distinti.
| insieme di operazioni primitive che un livello offre al livello superiore. Come tali operazioni siano implementate non riguarda il livello superiore. | |
| insieme di regole che governano il formato ed il significato delle informazioni (messaggi, frame, pacchetti) che le peer entity si scambiano fra loro. Le entità usano i protocolli per implementare i propri servizi. |
Nota: una ipotetica primitiva send_packet(), alla
quale l'utente fornisce il puntatore a un pacchetto già
assemblato, non è conforme a questa filosofia.
1.3.9) Aspetti di progetto dei livelli |
Decisioni di progetto vanno prese, nei vari livelli, in merito a diverse problematiche. Le principali sono: