2) La sicurezza |
In generale, la sicurezza ha a che fare con i seguenti aspetti:
La rete Internet è nata con la finalità originaria
di offrire un efficace strumento per lo scambio di informazioni
fra gruppi di ricercatori sparsi per il mondo. Di conseguenza
le problematiche relative alla sicurezza non sono state prese
in considerazione nel progetto dell'architettura TCP/IP, né
tantomeno in quello dei protocolli di livello application.
L'interesse mostrato da chi sfrutta commercialmente Internet,
però, sta cambiando la tipologia di utilizzo della rete,
e i problemi legati alla scarsa sicurezza diventano sempre più
pesanti, per cui ci sono molte attività in corso (compresa
la riprogettazione di alcuni protocolli fondamentali quali IP)
per incorporare nell'architettura meccanismi di sicurezza.
Nel caso specifico del Web, il fatto che esso sia nato come sistema
aperto e disponibile a tutti lo rende particolarmente vulnerabile
dal punto di vista della sicurezza (ovviamente, un sistema chiuso
è piu facile da proteggere). Ciò nonostante, alcuni
meccanismi sono disponibili e verranno brevemente descritti nel
seguito.
2.1) Controllo dei diritti di accesso |
2.1.1) Basic authentication in HTTP 1.0 |
Nel protocollo HTTP è presente un servizio
detto Basic Authentication
per fornire selettivamente l'accesso a informazioni private, sulla
base di un meccanismo di gestione di password.
Sul server si mantengono, in opportuni file di configurazione:
Un realm è di fatto una stringa di testo. Tutti i documenti
la cui URL contiene quella stringa fanno parte del realm.
Quando arriva una richiesta GET per un documento che appartiene
a un realm, il server non restituisce il documento, ma un messaggio
come questo:
HTTP/1.0 401 Unauthorized WWW-Authenticate: Basic realm="NomeRealm" Server: ..... Date: ..... Content-type: ..... Content-length: 0
Quando il client riceve questo messaggio, fa apparire automaticamente
una finestra di dialogo predisposta per l'immissione di una username
e di una password.
L'utente immette i dati, e poi preme OK. A questo punto il client
invia una nuova richiesta al server, simile alla seguente:
GET url(la stessa di prima) HTTP/1.0 Authorization: Basic ***************** User-agent: ..... Accept: ..... ecc.
dove il testo rappresentato con gli asterischi contiene la username
e la password immesse dall'utente, codificate con il metodo base64
encoding (uno standard del mondo Unix, definito
negli rfc 1341 e 1521, che non costituisce una cifratura ma serve
solo a poter trasmettere caratteri ASCII estesi).
Quando il server riceve la richiesta, applica l'algoritmo di decodifica
alla stringa di username-password, le confronta con quelle in
suo possesso per il realm NomeRealm e:
403
forbidden).
Il client di norma ricorda in una cache la coppia username-password
immessa dall'utente e la utilizza anche per i successivi accessi
a documenti dello stesso realm; il server deve comunque decodificare
tale coppia ogni volta che arriva e verificarne la corrispondenza
con quelle in suo possesso.
2.1.2) Digest authentication in HTTP 1.1 |
Il problema con questo approccio è
che username e password di fatto viaggiano in chiaro sulla rete,
dato che gli algoritmi usati per la codifica e la decodifica sono
noti a tutti, e quindi può essere intercettata.
In proposito c'è una proposta (Digest
Authentication, rfc 2069) per istituire un meccanismo
di cifratura di username e password basato sul meccanismo di Message
Digest, una sorta di funzione hash facile da calcolare
ma difficile da invertire (la vedremo più avanti).
Questo protocollo è di tipo challenge-response dove:
In questo modo i dati riservati dell'utente (username e password)
non viaggiano mai in chiaro sulla rete.
Quando il server riceve il Message Digest dal client, effettua
anch'esso un identico calcolo e confronta i due valori. Se sono
uguali è tutto OK, altrimenti no.
2.1.3) Firewall |
In molte situazioni in cui esiste una rete aziendale connessa con una rete esterna (ad esempio Internet), può sorgere la necessità di:
Questo si può ottenere per mezzo di un firewall
(parete tagliafuoco), che è l'incarnazione moderna del
fossato pieno d'acqua (e magari anche di coccodrilli) e del ponte
levatoio che proteggevano gli antichi castelli.
Il principio è lo stesso:
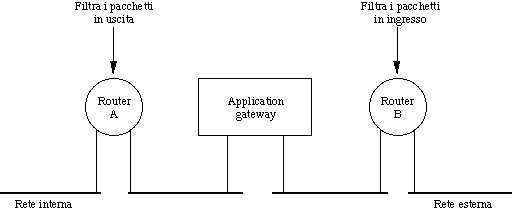
Il firewall si inserisce fra la rete aziendale e quella esterna.
In tal modo, tutto il traffico dall'una all'altra parte deve per
forza transitare attraverso il firewall.
Esistono molte configurazioni di firewall, più o meno raffinate. In quella sopra illustrata si ricorre a due tipi di componenti:
Criteri tipici di filtraggio dei pacchetti, che possono anche essere combinati fra loro, sono:
Possono esistere vari application gateway, uno per ogni protocollo
di livello application che si vuole controllare.
Spesso, per semplificare il controllo, si installa sulla rete
interna un server proxy
(che può anche coincidere col gateway), cioè un
oggetto che agisce da intermediario fra i clienti della rete interna
ed i serventi della rete esterna.
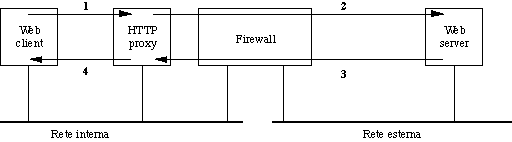
Ad esempio, nel caso di un server proxy per il protocollo HTTP (HTTP proxy) si ha tipicamente una situazione come questa:
Quando un utente attiva un link che punta a un server Web della rete esterna succede questo:
I proxy server hanno anche una funzione di caching
delle pagine più recenti, in modo da poterle offrire immediatamente
se vengono richieste più di una volta, aumentando così
l'efficienza e diminuendo l'uso di banda trasmissiva.
Infine, un'ultima nota: se l'azienda vuole pubblicare all'esterno
sue informazioni (ad esempio con un server Web) basterà
che collochi tale server all'esterno del firewall.
2.2) Protezione delle risorse da danneggiamento |
Di norma i server Web non accettano altri
metodi che GET (e POST in relazione alle form), quindi impediscono
operazioni pericolose quali la scrittura o la cancellazione di
file. Inoltre, di norma i server Web non considerano legali le
URL che fanno riferimento a porzioni del file system esterne alla
parte di competenza del server Web stesso.
Dunque, per lo meno quando si chiedono al server servizi standard
(per il recupero di pagine Web) non ci sono grandi pericoli.
2.2.1) La sicurezza e le estensioni del Web |
Il discorso però cambia completamente quando si allargano le funzionalità rese disponibili:
In entrambi i casi, le opportunità per azioni che causano
danneggiamenti travalicano le possibilità di controllo
di client e server, e dipendono esclusivamente dalle caratteristiche
dei programmi esterni. Si possono aprire delle voragini nella
sicurezza!
Essenzialmente, si può dire questo:
Lato client
Supponiamo che l'utente abbia configurato il suo client per lanciare
un interprete PostScript
quando riceve un file PostScript, che di norma contiene un insieme
di comandi per la formattazione di testo e grafica indipendenti
dalla piattaforma.
In questo scenario, l'interprete PostScript viene lanciato ed
esegue uno a uno i comandi contenuti nel file, mostrando sul video
(o stampando) il documento.
Ora, PostScript è un completo linguaggio di programmazione,
e contiene anche comandi per operazioni sul file system. Se l'autore
del documento PostScript ha sfruttato tali potenzialità
per recare danni, l'utente ne sopporterà le conseguenze:
ad esempio, il file PostScript potrebbe contenere delle istruzioni
che cancellano tutti i file dal disco rigido dell'elaboratore.
Lato server
Uno scenario tipico, come abbiamo già detto, è questo:
Abbiamo visto che nel caso di una interrogazione a una base dati:
Ora, se invece:
allora si corrono enormi rischi: un utente remoto può inviare
un comando per distruggere dei file, ricevere il file delle password,
eccetera.
Alcune delle possibili precauzioni per evitare le situazioni sopra descritte sono le seguenti:
2.2.2) La sicurezza e Java |
Una grande attenzione è stata posta,
nel progetto del linguaggio e della JVM, ai problemi di sicurezza
derivanti potenzialmente dal fatto di mandare in esecuzione sulla
propria macchina un codice proveniente da una fonte ignota (e
perciò non affidabile in linea di principio).
Ad esempio, si potrebbero ipotizzare questi scenari certamente indesiderabili:
La prima linea di difesa è stata incorporata nel linguaggio, che è:
In tal modo è impossibile accedere a zone di memoria esterne
a quelle allocate all'applet.
Tuttavia, Trudy (un personaggio
che conosceremo di più in seguito) si diverte a modificare
un compilatore C per produrre dei bytecode in modo da aggirare
i controlli effettuati dal compilatore Java.
Per questa ragione, la JVM offre la seconda linea di difesa sotto forma di una componente, detta bytecode verifier, che effettua numerosi controlli sui bytecode prima di mandarli in esecuzione, verificando ad esempio che non si cerchi di:
La terza linea di difesa è rappresentata dal class
loader, il meccanismo di caricamento delle classi.
Esso impedisce, ad esempio, che una classe dell'applet vada a
sostituirsi a una delle classi di sistema in modo da aggirare
i meccanismi di sicurezza di quest'ultima.
Infine, un'ulteriore linea di difesa è il security
manager, una classe che ha il compito di stabilire
dei limiti a ciò che il programma (applet o application)
può fare.
In particolare, di norma i client Web (e gli AppletViewer) caricano all'avvio un security manager che impedisce a tutti gli applet di:
Viceversa, un'applicazione Java viene avviata di norma senza alcun
security manager associato (a meno che non venga programmata diversamente),
e quindi non ha alcuna delle limitazioni sopra citate.