Appunti del corso di ARCHITETTURA DEGLI ELABORATORI
Autore: professor Giovanni Chiola; email:
chiola@disi.unige.it
Copyright © 1996-2002.
Scopo di questo capitolo é lo studio della struttura interna
delle macchine convenzionali, a livello di trasferimento di dati tra registri
(RTL, ovvero, Register Transfer Level).
Siccome il corso deve mantenere un carattere introduttivo lo studio verrŕ
limitato alla struttura interna della CPU, facendo ove possibile riferimento
ad un esempio didattico molto semplificato rispetto ad un caso "reale".
Normalmente per questioni di semplicitŕ descrittiva, la microarchitettura
di una qualsiasi macchina convenzionale viene suddivisa in due parti:
il cosiddetto Data Path dove vengono definiti i "percorsi"
che devono seguire i dati per portare a termine l'elaborazione richiesta,
passando da un registro ad un altro in grado di memorizzare i risultati parziali;
la parte di Controllo che ha lo scopo di fornire ai dispositivi
presenti nel data path i segnali di controllo necessari per portare a termine
i diversi passi elementari della computazione.
Data Path e Controllo vengono solitamente progettati in modo separato: prima
viene definito il Data Path a partire dalla specifica delle istruzioni della
macchina convenzionale che si vuole realizzare, poi si progetta il Controllo
atto a far operare il Data Path nel modo richiesto.
Ovviamente la progettazione di un sistema é una attivitŕ molto
complessa, che prevede normalmente diversi momenti in cui i progettisti possono
"tornare a riconsiderare" l'opportunitŕ di decisioni giŕ prese,
alla luce delle difficoltŕ che possono sorgere nella realizzazione di
altri parti, cercando ove possibile di arrivare a compromessi ottimali tra
la complessitŕ di realizzazione del Data Path e del Controllo.
Mentre per la progettazione del Data Path non sono state individuate alternative
radicalmente diverse tra loro e ci si riconduce sempre alla progettazione di
un circuito sequenziale sincrono in cui i registri della macchina convenzionale
fungono da elementi di memoria di tipo Master/Slave, per la progettazione del
Controllo sono stati storicamente seguiti due approcci diversi: una realizzazione
detta "cablata" che corrisponde alla progettazione di un normale circuito
sequenziale sincrono, oppure una realizzazione detta "microprogrammata".
Una struttura di controllo di tipo microprogrammato risulta essere particolarmente
interessante da studiare dal punto di vista didattico, in quanto fornisce un
esempio di realizzazione di una parte di una macchina programmabile facendo
uso di una macchina virtuale programmabile piů semplice (e quindi
direttamente realizzabile senza troppo sforzo con l'approccio "cablato").
Dal punto di vista pratico, la "bellezza" della microprogrammazione viene
pagata in termini di prestazioni ottenibili dal dispositivo.
Quindi realizzazioni particolarmente efficaci di una macchina convenzionale
tendono oggi ad evitare l'introduzione del livello di microprogrammazione,
dando luogo alle cosiddette "architetture RISC".
Passiamo ora a descrivere un esempio di microarchitettura inventata
di sana pianta.
Questa macchina ipotetica, che chiameremo con la sigla VM-1
(macchina virtuale di livello 1), ha lo scopo di realizzare fisicamente
la macchina convenzione VM-2 descritta
in precedenza utilizzando un approccio microprogrammato
per il Controllo.
Anche la struttura del sistema VM-1, cosě come quella di tutte le CPU
piů complesse, puň essere decomposta in due parti
fondamentali: il Data Path e la parte di
Controllo.
Il Data Path di una microarchitettura contiene tutti i registri, i bus
interni per lo spostamento dei dati e l'unitŕ aritmetico logica.
La parte di controllo ha lo scopo di generare la corretta sequenza
di segnali di controllo per pilotare i dispositivi (sincroni e combinatori)
presenti nel Data Path.
La struttura del Data Path di VM-1 é illustrata in figura:
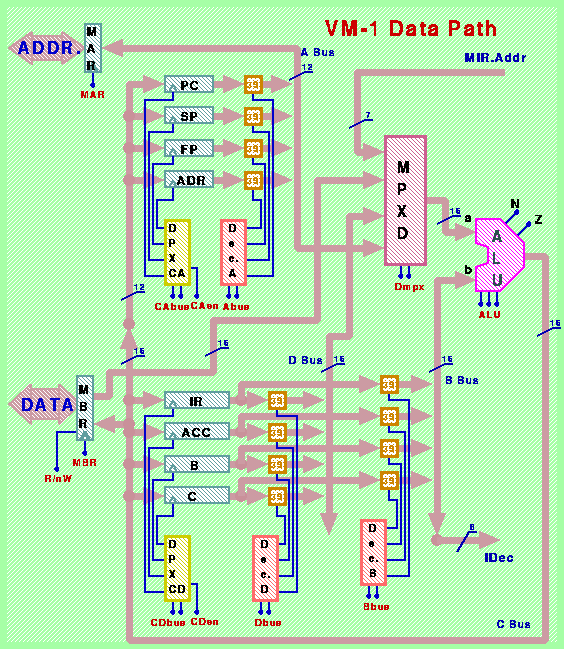
Si compone di 4 registri a 12 bit destinati a contenere indirizzi,
4 registri a 16 bit destinati a contenere dati, due registri chiamati
MAR (Memory Address Register) e MBR (Memory Buffer Register) per
stabilire la comunicazione col bus di sistema
(che verrŕ definito in seguito), un'ALU capace di compiere
8 operazioni elementari su operandi a 16 bit, e 5 bus interni.
Il bus chiamato B permette di connettere uno dei quattro registri
IR, ACC, B e C all'ingresso "b" dell'ALU.
Gli 8 fili corrispondenti ai bit piů significativi del bus B
sono anche riportati in ingresso ad un circuito combinatorio chiamato
IDec (appartenente alla parte di controllo della CPU) destinato ad
effettuare la decodifica del codice operativo ad espansione delle
istruzioni VM-2.
L'ingresso "a" dell'ALU puň essere connesso in alternativa
al bus A, al bus D, al registro MBR, oppure ad un campo del registro
MIR (appartenente alla parte di controllo della CPU), grazie ad un
multiplexer chiamato MPXD a 4 posizioni, ciascuna da 16 bit.
Notare che, mentre il bus D ed il registro MBR sono da 16 bit,
il bus A é da 12 bit ed il campo Addr del registro MIR é
da 7 bit: negli ultimi due casi, i fili in ingresso sono connessi
ai corrispondenti fili meno significativi dell'uscita, mentre i rimanenti
fili piů significativi dell'uscita sono connessi alla costante "0".
Il bus D consente di riportare il valore di uno dei registri a 16 bit
anche sull'ingresso "a" dell'ALU, mentre il bus A consente di portare
il valore di uno dei quattro registri a 12 bit chiamati PC, SP,
FP e ADR in ingresso al registro MAR e/o sull'ingresso "a" dell'ALU.
L'uscita dell'ALU comanda il bus C, mediante il quale possono essere
inseriti nuovi valori in tutti i registri della CPU ad eccezione di
MAR.
La prima parte del bus C (chiamata CD, per convenzione) consta di 16 bit,
ed é connessa agli ingressi dei registri MBR, IR, ACC, B e C.
Successivamente, il bus C prosegue con i soli 12 bit meno significativi
della rappresentazione (e viene chiamato bus CA) per connettere gli
ingressi dei registri PC, SP, FP e ADR all'uscita dell'ALU.
L'ALU é in oltre dotata di due uscite binarie chiamate N e Z,
che identificano le due condizioni "valore in uscita negativo"
e "valore in uscita uguale a zero".
Tali uscite ausiliarie sono connesse alla parte di controllo della
CPU per la realizzazione delle istruzioni di salto condizionale.
Il caricamento di nuovi valori nei registri viene comandato
attraverso il loro ingresso di controllo Clock (evidenziato col
triangolino per denotare il funzionamento di tipo edge triggered
caratteristico dei registri di tipo Master/Slave).
Il registro MBR ha in piů un segnale di controllo chiamato
"R/nW" per scegliere se usare il valore presente sul bus interno CD
(se R/nW = 0) oppure i fili dati del bus
di sistema (se R/nW = 1) come configurazione da memorizzare.
Passiamo ora ad esaminare la struttura della parte di controllo della CPU.
VM-1 illustrata in figura:
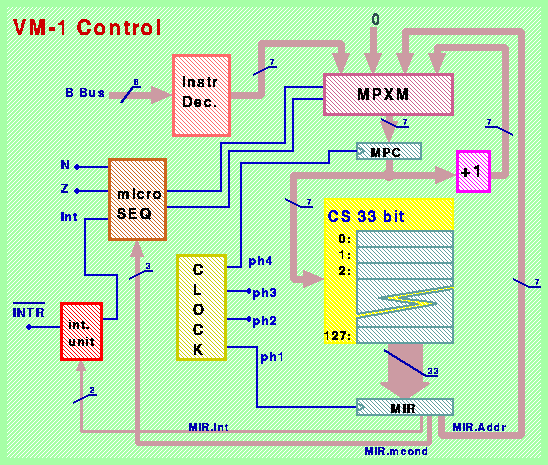
La struttura di controllo é microprogrammata,
ovvero composta da una macchina virtuale di livello L1 che esegue
un (micro) programma di emulazione delle istruzioni di livello L2
contenuto in una memoria a sola lettura chiamata Control Store (CS).
Nella fattispecie, il CS é composto da 128 parole di 33 bit.
Il contenuto del CS viene indirizzato mediante un registro chiamato
Micro Program Counter (MPC) a 7 bit, ed il contenuto della parola
indirizzata viene copiato nel registro a 33 bit chiamato Micro
Instruction Register (MIR).
Il funzionamento nel tempo della CPU viene scandito dal susseguirsi
di 4 segnali di clock, chiamati "ph1", "ph2", "ph3" e "ph4".
Il dispositivo chiamato CLOCK provvede a generare 4 segnali periodici
come illustrato in figura:
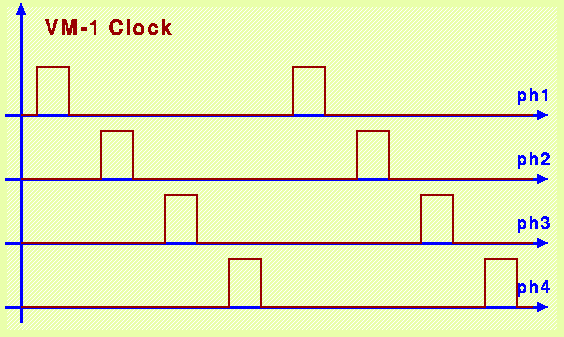
La fase 4 del clock comanda il caricamento di un nuovo indirizzo nel
registro MPC, mentre la successiva variazione della fase 1 del clock
comanda il caricamento del contenuto della nuova cella di CS nel
registro MIR, consentendo quindi il passaggio dall'esecuzione della
microistruzione precedente all'esecuzione della microistruzione
successiva.
L'indirizzo da caricare nel registro MPC viene scelto ad ogni passo
tra 4 alternative mediante il multiplexer MPXM: valore successivo
(proveniente dal circuito incrementatore +1), valore specificato dai
7 bit del campo Addr della microistruzione precedente, valore 0 (reset
della macchina), oppure valore prodotto dal circuito combinatorio
"Instr Dec." in funzione degli 8 bit piů significativi presenti
sul Bus B del Data Path.
La scelta del prossimo indirizzo da caricare in MPC viene effettuata
dal circuito combinatorio "micro SEQ" in funzione dei valori binari
N e Z prodotti dall'ALU, del valore binario Int prodotto dal dispositivo
"int. unit", e dalla configurazione dei 3 bit del campo "mcond" del
registro MIR.
Le fasi 2 e 3 del clock vengono usate per comandare il caricamento di
valori nei registri del Data Path: la fase 2 comanda il caricamento
del registro MAR, mentre la fase 3 comanda il caricamento di tutti
gli altri registri del Data Path connessi al Bus C.
La struttura del registro MIR é illustrata nella seguente
tabella:
Il significato dei diversi campi é quello di controllare
il funzionamento dei dispositivi che costituiscono la CPU, secondo
la seguente codifica:
-
ALU (3 bit)
- determina l'operazione portata a termine dall'ALU,
e di conseguenza il valore disponibile (dopo il tempo
di assestamento dei circuiti combinatori) sul Bus C:
000
- alu = ingr.a
001
- alu = NOT ingr.a
010
- alu = ingr.a<<1 (scorrimento a sinistra)
011
- alu = ingr.a>>1 (scorrimento a destra)
100
- alu = ingr.a + 1
101
- alu = ingr.a - 1
110
- alu = ingr.a + ingr.b
111
- alu = ingr.a AND ingr.b
-
CS (1 bit)
- Segnale di controllo Chip Select per l'attivazione del
Bus di sistema per un
ciclo di Lettura e Scrittura di una cella di memoria RAM:
0
- bus di sistema disabilitato;
1
- bus di sistema attivato.
-
R/nW (1 bit)
- Segnale di controllo per la scelta del tipo di accesso
alla memoria RAM tramite il bus di sistema:
0
- scrittura in memoria;
1
- lettura dalla memoria.
-
MAR (1 bit)
- Segnale di abilitazione al caricamento del valore presente sul
Bus A nel registro MAR:
0
- MAR mantiene il vecchio valore;
1
- MAR carica il nuovo valore.
-
-
MBR (1 bit)
- Segnale di abilitazione al caricamento di un nuovo valore
nel registro MBR, in combinazione col valore del campo
R/nW
0
- MBR mantiene il vecchio valore;
1
- MBR carica il nuovo valore: dai fili dati del bus di sistema
se R/nW=1, dal Bus C altrimenti.
-
Dmpx (2 bit)
- controlla la connessione del multiplexer sull'ingresso a dell'ALU:
00
- ALU.ingr.a = Bus A
01
- ALU.ingr.a = Bus D
10
- ALU.ingr.a = MBR
11
- ALU.ingr.a = campo Addr del registro MIR
-
Abus (2 bit)
- Scelta di uno dei quattro registri a 12 bit per la connessione
al bus A:
-
00
- Bus A = PC (Program Counter)
-
01
- Bus A = SP (Stack Pointer)
-
10
- Bus A = FP (Frame Pointer)
-
11
- Bus A = ADR (Auxiliary Address)
-
Bbus (2 bit)
- Scelta di uno dei quattro registri a 16 bit per la connessione
al bus B:
00
- Bus B = IR (Instruction Register)
01
- Bus B = ACC (Accumulatore)
10
- Bus B = B (Auxiliary register B)
11
- Bus B = C (Auxiliary register C)
-
CAbus (2 bit)
- Scelta di uno dei quattro registri a 12 bit per la connessione
al bus C per l'inserimento di un nuovo valore (inserimento
condizionato al valore del campo CAen:
00
- PC <- Bus C (Program Counter)
01
- SP <- Bus C (Stack Pointer)
10
- FP <- Bus C (Frame Pointer)
11
- ADR <- Bus C (Auxiliary Address)
-
CAen (1 bit)
- Abilitazione alla scrittura del valore presente sul bus C
per il registro a 12 bit scelto attraverso il campo CAbus:
0
- mantiene il vecchio valore dei registri a 12 bit;
1
- carica il nuovo valore presente sul Bus C nel
registro a 12 bit individuato dal campo
CAbus.
-
CDbus (2 bit)
- Scelta di uno dei quattro registri a 16 bit per la connessione
al bus C per l'inserimento di un nuovo valore (inserimento
condizionato al valore del campo CDen:
00
- IR <- Bus C (Instruction Register)
01
- ACC <- Bus C (Accumulatore)
10
- B <- Bus C (Auxiliary register B)
11
- C <- Bus C (Auxiliary register C)
-
CDen (1 bit)
- Abilitazione alla scrittura del valore presente sul bus C
per il registro a 16 bit scelto attraverso il campo
CDbus:
0
- mantiene il vecchio valore dei registri a 16 bit;
1
- carica il nuovo valore presente sul Bus C nel
registro a 16 bit individuato dal campo
CDbus.
-
Dbus (2 bit)
- Scelta di uno dei quattro registri a 16 bit per la connessione
al bus D:
00
- Bus D = IR (Instruction Register)
01
- Bus D = ACC (Accumulatore)
10
- Bus D = B (Auxiliary register B)
11
- Bus D = C (Auxiliary register C)
-
Int (2 bit)
- controlla le interruzioni (questo dispositivo viene
descritto per completezza, ma la macchina didattica che
discuteremo non farŕ uso di interruzioni, per
semplicitŕ di esposizione) secondo la seguente codifica:
00
- Interrupt no-op
(non cambia lo stato rispetto alle interruzioni)
01
- Interrupt reset (annulla le richieste e diventa insensibile)
10
- Interrupt enable (diventa sensibile alle richieste)
11
- Interrupt disable (diventa insensibile alle richieste)
-
mcond (3 bit)
- scelta della prossima microistruzione da eseguire (realizzata
mediante la commutazione del multiplexer MMPX):
000
- microcodice sequenziale (MPC = MPC + 1)
001
- micro salto non condizionale (MPC = MIR.Addr)
010
- micro salto condizionale N (if N then MPC = MIR.Addr
else MPC = MPC + 1)
011
- micro salto condizionale Z (if Z then MPC = MIR.Addr
else MPC = MPC + 1)
100
- reset microprogramma (MPC = 0)
101
- L2 instruction decode (MPC = decode(Bus B))
110
- micro salto condizionale se Interrupt
(if Interrupt then MPC = MIR.Addr else MPC = MPC + 1)
-
Addr (7 bit)
- indirizzo della prossima microistruzione da eseguire in caso di
salto di microistruzione.
Il funzionamento della microarchitettura VM-1, come tutti i circuiti
sequenziali sincroni, é cadenzato dalle variazioni del Clock,
dalla cui frequenza dipende la velocitŕ di esecuzione delle
istruzioni.
D'altra parte, la frequenza di variazione del clock non puň
essere fissata a valori arbitrariamente alti, in quanto i dispositivi
del Data Path e del Controllo devono avere il tempo per produrre in
uscita i risultati corretti a fronte dei nuovi dati in ingresso.
Ottenere un dispositivo VM-1 veloce dipende quindi da dalla progettazione
di tutta la microarchitettura in modo tale da consentire il raggiungimento
della massima frequenza di clock.
Il criterio da seguire é quello di individuare i "percorsi critici"
dei dati attraverso i dispositivi in modo da determinare il minimo
periodo di clock necessario per dar tempo ai dati di fluire attraverso
il percorso critico "piů lento".
La durata massima consentita per un percorso dei dati viene definita dagli
istanti di variazione di clock corrispondenti alla memorizzazione dei valori
nei registri.
Partendo dall'inserzione di nuovi dati in un registro, occorre verificare
che i circuiti combinatori le cui uscite dipendono dal valore memorizzato
in quel registro siano in grado di produrre il valore corretto in uscita
prima che questo valore sia, a sua volta, memorizzato in un altro registro.
Il Control Store é una unitŕ di memoria a sola lettura
(ROM) contenente il microprogramma che consente alla macchina virtuale
VM-1 di interpretare il comportamento che abbiamo specificato per la
macchina convenzionale VM-2.
La memoria é organizzata in 128 celle da 33 bit ciascuna.
La struttura delle celle di memoria é concettualmente identica
alla struttura del registro MIR: il caricamento di un valore dal CS
al registro MIR, e l'uso dei vari campi per controllare l'attivitŕ
dei dispositivi che costituiscono la microarchitettura, corrisponde
all'esecuzione di una microistruzione, ovvero di un passo elementare che
concorre al fetch, decodifica o esecuzione di una istruzione della
macchina convenzionale.
Cominciamo quindi a vedere un esempio di inizializzazione
della macchina convenzionale VM-2 e di fetch
e decodifica di una istruzione realizzate
mediante una sequenza di microistruzioni allocate dall'indirizzo 0 del CS:
| cella |
|
| 0 |
|
RESET: |
(PC <- 0; reset Interrupt) |
| 1 |
|
FETCH: |
(if Interrupt then goto 6) |
| 2 |
|
|
(MAR <- PC; PC <- PC+1; start read) |
| 3 |
|
|
(MBR <- data bus; end read) |
| 4 |
|
|
(IR <- MBR; ADR <- MBR) |
| 5 |
|
|
(MPC <- decode(IR)) |
Il circuito di decodifica produce automaticamente l'indirizzo della cella
di CS che contiene la prima microistruzione per completare l'esecuzione
dell'istruzione della macchina convenzionale.
Il circuito combinatorio di decodifica é realizzato in modo tale
che l'istruzione JPOS (codice operativo
0000) genera l'indirizzo 32,
l'istruzione JNEG (codice operativo
0001) genera l'indirizzo 34,
ecc., sino all'istruzione LSHF (codice
operativo 11111111) che genera l'indirizzo 126.
Procediamo quindi con l'analisi del microcodice che realizza l'esecuzione
di alcune istruzioni VM-2:
| cella |
|
| 32 |
|
JPOS: |
(ALU = ACC; if N then goto 1) |
| 33 |
|
|
(PC <- IR; goto 1) |
| 34 |
|
JNEG: |
(ALU = ACC; if N then goto 33) |
| 35 |
|
|
(goto 1) |
| 36 |
|
JZER: |
(ALU = ACC; if Z then goto 33) |
| 37 |
|
|
(goto 1) |
| 38 |
|
JNZE: |
(ALU = ACC; if Z then goto 1) |
| 39 |
|
|
(PC <- IR; goto 1) |
Notare la similitudine tra le realizzazioni dei diversi tipi di salto
condizionale, che permette una certa condivisione del microcodice una volta
stabilito se effettuare o meno il salto di programma.
Questa tecnica di riutilizzo del microcodice per portare a termine istruzioni
diverse puň essere sfruttata anche per istruzioni che differiscono nel
modo di indirizzamento.
Proviamo infatti a confrontare la realizzazione delle istruzioni con
indirizzamento diretto e quelle con indirizzamento indicizzato rispetto
al registro FP:
| cella |
|
| 40 |
|
LODD: |
(MAR <- ADR; start read) |
| 41 |
|
|
(MBR <- data bus; end read; goto 49) |
| 42 |
|
ADDD: |
(MAR <- ADR; start read) |
| 43 |
|
|
(MBR <- data bus; end read; goto 51) |
| 44 |
|
ANDD: |
(MAR <- ADR; start read) |
| 45 |
|
|
(MBR <- data bus; end read; goto 53) |
| 46 |
|
STOD: |
(MAR <- ADR; MBR <- ACC; start write) |
| 47 |
|
|
(end write; goto 1) |
| 48 |
|
LODL: |
(ADR <- FP+IR; goto 40) |
| 49 |
|
|
(ACC <- MBR; goto 1) |
| 50 |
|
ADDL: |
(ADR <- FP+IR; goto 42) |
| 51 |
|
|
(ACC <- MBR + ACC; goto 1) |
| 52 |
|
ANDL: |
(ADR <- FP+IR; goto 44) |
| 53 |
|
|
(ACC <- MBR AND ACC; goto 1) |
| 54 |
|
STOL: |
(ADR <- FP+IR; goto 46) |
La realizzazione delle istruzioni JUMP
(indirizzo 56) e LDIX
(indirizzo 58) risulta a questo punto banale;
notare invece la complessitŕ della realizzazione dell'istruzione
CALL (indirizzo 60):
| cella |
|
| 56 |
|
JUMP: |
(PC <- IR; goto 1) |
| 57 |
|
|
(goto 1) |
| 58 |
|
LDIX: |
(ADR <- ACC+IR; goto 40) |
| 59 |
|
|
(goto 1) |
| 60 |
|
CALL: |
(MBR <- FP) |
| 61 |
|
|
(MAR <- SP; SP,B <- SP - 1; start write) |
| 62 |
|
|
(MBR <- PC; end write) |
| 63 |
|
|
(MAR <- SP; FP <- B + 1; start write) |
| 64 |
|
|
(SP <- SP - 1; end write; goto 56) |
Le istruzioni con codice espanso a 8 bit vengono mappate a partire
dall'indirizzo 96:
| cella |
|
| 96 |
|
LOC8: |
(B <- 0000000011111110) |
| 97 |
|
|
(B <- B + 1; goto 65) |
| 98 |
|
LOCH: |
(B <- IR<<1) |
| 99 |
|
|
(B <- B<<1; goto 66) |
| 100 |
|
INSP: |
(B <- 0000000011111110) |
| 101 |
|
|
(B <- B + 1; goto 76) |
| 102 |
|
DESP: |
(B <- 0000000011111110) |
| 103 |
|
|
(B <- B + 1; goto 78) |
| 104 |
|
PUSH: |
(MAR <- SP; MBR <- ACC; start write) |
| 105 |
|
|
(SP <- SP - 1; end write; goto 1) |
| 106 |
|
PSHI: |
(ADR <- ACC) |
| 107 |
|
|
(MAR <- ADR; start read; goto 81 ) |
Le istruzioni L2 che richiedono piů di due microistruzioni
per il completamento delle operazioni fanno uso di celle del CS
di indirizzo compreso tra 65 e 95:
| cella |
|
| 65 |
|
|
(ACC <- IR AND B; goto 1) |
| 66 |
|
|
(B <- B<<1) |
| 67 |
|
|
(B <- B<<1) |
| 68 |
|
|
(B <- B<<1) |
| 69 |
|
|
(B <- B<<1) |
| 70 |
|
|
(B <- B<<1) |
| 71 |
|
|
(B <- B<<1) |
| 72 |
|
|
(C <- 0000000011111110) |
| 73 |
|
|
(C <- C + 1) |
| 74 |
|
|
(ACC <- ACC AND C) |
| 75 |
|
|
(ACC <- ACC + B; goto 1) |
| 76 |
|
|
(B <- IR AND B) |
| 77 |
|
|
(SP <- SP + B; goto 1) |
| 78 |
|
|
(B <- IR AND B) |
| 79 |
|
|
(B <- NOT B) |
| 80 |
|
|
(B <- B + 1; goto 77) |
| 81 |
|
|
(MBR <- data bus; end read) |
| 82 |
|
|
(MAR <- SP; SP <- SP - 1; start write; goto 47) |
La definizione del microcodice per l'implementazione delle rimanenti
istruzioni viene lasciato per esercizio.