
Dopo aver visto l'esempio concreto, seppur semplificato, di una macchina microprogrammata proviamo a riconsiderare le scelte fatte nella organizzazione delle rappresentazioni binarie nel registro MIR, e quali implicazioni esse hanno sulla dimensione e sullo "stile" del microcodice necessario a realizzare le istruzioni della macchina convenzionale. Alcuni campi del registro MIR della macchina VM-1 sono stati codificati in modo da ridurre il numero di bit delle celle della CS rispetto al numero di bit necessari per pilotare i singoli dispositivi del Data Path, mentre altri no. Per esempio i bit MAR e MBR che specificano il caricamento negli omonimi registri non sono stati "compattati", mentre invece il caricamento di un valore nei registri IR, ACC, B e C viene controllato mediante una codifica "compatta" dei campi CDen e CDbus.
La microarchitettura VM-1 potrebbe essere modificata in modo da eliminare tutti questi "trucchi", per esempio prevedendo l'uso di 4 bit indipendenti per il caricamento di valori nei registri IR, ACC, B e C, cosņ come nella versione proposta come esempio avviene per i registri MAR e MBR. Analogamente anche i tre bit dei campi CAen e CAbus potrebbero essere sostituiti da 4 bit indipendenti per la memorizzazione di valori nei registri PC, SP, FP e ADR. Un tale approccio alla organizzazione di una microarchitettura viene chiamato microprogrammazione orizzontale perchĶ, se pensiamo ad un disegno "in scala" della CS, questa tende ad assumere una estensione in orizzontale (poche celle, molto larghe). Lo svantaggio ovvio della organizzazione orizzontale ķ l'aumento del numero di bit nel registro MIR e nelle celle della CS rispetto alla soluzione proposta. In compenso, in generale ci si pu“ aspettare di avere poi meno limitazioni nella microprogrammazione per quanto riguarda l'esecuzione simultanea di pi∙ passi elementari da parte di pi∙ dispositivi diversi del data path (aumento del "parallelismo" del microcodice), con una conseguente riduzione del cicli di clock e di microistruzione per realizzare una istruzione data.
Contrapposto all'approccio orizzontale, viene anche definita la microprogrammazione verticale, cosņ chiamata perchĶ tende invece a richiedere una CS contenente molte celle, ciascuna cella composta da pochi bit. Nel nostro esempio, un'approccio "pi∙ verticale" potrebbe essere seguito raggruppando i 4 registri a 16 bit (IR, ACC, B, C) ed i 4 registri a 12 bit (PC, SP, FP, ADR) in un'unico insieme di 8 registri, il cui caricamento pu“ essere comandato usando un campo Cen da 1 bit ed un campo Cbus da 3 bit (ossia 4 bit in totale, contro i 6 necessari nella microarchitettura VM-1). L'ovvio vantaggio in termini di riduzione del numero di bit nel registro MIR verrebbe in questo caso pagato con l'impossibilitÓ di caricare simultaneamente lo stesso valore in due registri diversi, che viene sfruttata per esempio nella microistruzione 4 della fase di fetch. In questo caso particolare uno dei due registri potrebbe essere caricato nella microistruzione successiva (quella di decodifica) senza nessuna perdita di cicli di clock, ma in generale restrizioni di questo genere, se non opportunamete vagliate, possono portare a scrivere microcodici pi∙ lunghi e/o pi∙ lenti da eseguire. Il caso estremo di un approccio verticale consiste nel definire una volta per tutte un insieme di N=2**k microistruzioni elementari, usando quindi k bit per la rappresentazione del codice della microistruzione all'interno della CS e del registro MIR. Se si arriva a questo estremo, allora occorrerÓ aggiungere un circuito combinatorio di decodifica che a partire dal numero (tra 0 ed N-1) della microistruzione, generi i segnali di controllo atti a pilotare i dispositivi del Data Path.
In alternativa ad una realizzazione microprogrammata, come giÓ accennato in precedenza, possiamo pensare ad una realizzazione cablata del Controllo di una microarchitettura. In questo caso, per“, occorre ridurre al minimo la complessitÓ delle sequenze dei segnali di controllo per poter arrivare a progettare e realizzare il dispositivo. Normalmente una realizzazione in logica cablata del controllo viene oggi realizzata solo per macchine convenzionali particolari, concepite seguendo il cosidetto approccio RISC (Reduced Instruction Set Computer). In estrema sintesi, l'idea di una macchina RISC ķ quella di definire soltanto un insieme di istruzioni "particolarmente semplici" da realizzare, ed in particolare realizzabili usando un solo ciclo del Data Path (e quindi un solo periodo di Clock). Questo corrisponderebbe ad una macchina microprogrammata nella quale tutte le istruzioni corrispondono ad una e una sola microistruzione. Tale assunzione sull'insieme delle istruzioni della macchina convenzionale permette di realizzare in modo semplice tutta una serie di ottimizzazioni della realizzazione (incluso la sostituzione del controllo microprogrammato con un controllo cablato) che consentono di ottenere dispositivi molto pi∙ veloci a paritÓ di tecnologia usata. L'approccio RISC viene poi giustificato osservando che, in realtÓ le istruzioni pi∙ semplici sono anche quelle eseguite con maggior frequenza in una macchina convenzionale, per cui l'emulazione occasionale mediante estensione procedurale di altre istruzioni pi∙ complesse non comporta svantaggi pratici apprezzabili in termini di prestazioni.
Abbiamo giÓ visto (parlando della realizzazione dei moduli RAM) la possibilitÓ di usare dispositivi a 3 stati di uscita per la realizzazione fisica di una connessione che, in tempi diversi, permette di condividere gli stessi fili per portare dati provenienti da sorgenti diverse verso destinazioni diverse. Per poter operare correttamente, tali dispositivi necessitano di un protocollo di coordinamento che impedisca l'invio simultaneo di pi∙ valori sullo stesso filo. Nel caso della connessione tra CPU e moduli RAM la situazione ķ particolarmente semplice a causa della asimmetria dei dispositivi: la CPU svolge un ruolo attivo mandando delle richieste di lettura o di scrittura, mentre i moduli RAM si limitano a "rispondere" alle richieste, e non prendono mai l'iniziativa di iniziare una comunicazione. Una tale situazione la possiamo generalizzare introducendo il concetto di relazione Master/Slave nella comunicazione. L'idea di Bus ķ proprio imperniata sulla relazione Master/Slave che sussiste tra la CPU (Master) e gli altri dispositivi (Slave) durante le operazioni di scambio di informazioni (lettura o scrittura di dati).
Il rispetto della condizione di "non collisione" di pi∙ valori sugli stessi fili, tuttavia, ķ una condizione necessaria ma non sufficente per la realizzazione corretta delle operazioni di scambio delle informazioni tra il Master e lo Slave. Occorre infatti che le due entitÓ coinvolte si coordinino nel tempo per portare a termine con successo lo scambio dei dati. Ciascuna delle due entitÓ deve infatti aspettare che l'altra abbia inserito i propri dati sui fili prima di memorizzare i dati presenti sui fili stessi. Inoltre, chi invia i dati deve continuare ad inviarli fina a quando non ha la certezza che l'altra entitÓ li ha ricevuti correttamente e memorizzati. Questa sincronizzazione tra Master e Slave viene ottenuta adottando un opportuno protocollo sincrono o asincrono.
Anche in questo caso, volendo pensare ad una realizzazione di un protocollo per coordinare nel tempo le attivitÓ del Master e dello Slave durante una comunicazione mediante bus, possiamo trovare due tipi di soluzioni diverse, chiamate sincrone e asincrone.
Cominciamo a descrivere un protocollo asincrono particolarmente semplice ed "elegante": il cosiddetto handshaking a due variabili. Ne diamo una descrizione informale, chiamando M la variabile binaria prodotta dal Master e "letta" dallo Slave, ed S la variabile binaria prodotta dallo Slave e letta dal Master. La condizione iniziale "di riposo" (ossia in assenza di comunicazioni sul bus) prevede che le due variabili assumano il valore M=S=0. Solo il Master pu“ prendere l'iniziativa di comunicare, e lo fa aspettando che S assuma il valore 0 e poi ponendo M=1. Nella condizione di "riposo" lo slave rimane ad osservare il valore di M (... gli schiavi non hanno diritto di riposare ...): non appena verifica la transizione di M da 0 a 1, interpreta questa transizione come la ricezione di un ordine di comunicazione, e passa ad eseguirlo immediatamente, lasciando sempre a 0 la variabile S. Una volta terminata l'esecuzione dell'ordine ricevuto, lo Slave pone S=1 e si rimette ad osservare il valore di M, rimanendo in vigile attesa per tutto il tempo in cui trova M=1. Il Master, una volta posto M=1, si mette ad osservare il valore di S, rimanendo in vigile attesa per tutto il tempo in cui trova S=0; quando finalmente vede la transizione di S da 0 a 1 allora prende nota del fatto che lo Slave ha terminato l'esecuzione dell'ordine, quindi, dopo aver eventualmente usato i risultati prodotti dallo Slave, decide di terminare la comunicazione ponendo M=0. Una volta posto M=0, il Master ha finito di usare il bus, ma non pu“ procedere immediatamente ad inviare un nuovo ordine se non dopo aver verificato che anche la variabile S ķ tornata ad assumere il valore 0. Da parte sua, lo Slave mantiene attiva la sua connessione sul bus dopo aver posto S=1 per tutto il tempo in cui osserva M=1; quando finalmente si accorge della transizione di M da 1 a 0, allora "si stacca" dal bus e poi pone S=0, consentendo quindi al Master di inviargli eventualmente un nuovo comando.
Tale schema di comunicazione asincrona si presta altrettanto bene per la realizzazione di cicli di lettura e di scrittura di dati in RAM da parte della CPU. Nel caso della lettura, la comunicazione ķ bidirezionale: il Master manda l'indirizzo, lo slave risponde con il dato relativo. Nel caso della scrittura, la comunicazione ķ unidirezionale: il Master manda l'indirizzo ed il dato, lo slave esegue il comando e deve solo dare la conferma dell'avvenuta scrittura seguendo il protocollo. Proviamo a formalizzare un ciclo di LETTURA asincrona:
Il maggior pregio di questo handshaking coincide col suo maggior difetto, e consiste nel costringere sia il Master che lo Slave a "rallentare" la loro attivitÓ quel tanto che basta per aspettare che l'altro abbia risposto correttamente. Se da un lato questo consente di progettare e realizzare il protocollo in modo totalmente independente dalle temporizzazioni dei dispositivi e dei fili di comunicazione (ricordiamo che la propagazione di un segnale elettrico su un filo richiede tempi dell'ordine di 4-5 ns/m, per cui pu“ diventare un fattore determinante per fili di connessione abbastanza lunghi), dall'altro impone degli ulteriori ritardi che non sono insiti nella comunicazione che si vuole realizzare, ma che servono solo a scambiare "convenevoli" tra il Master e lo Slave dopo la conclusione della comunicazione, come nel caso degli ultimi due stati del ciclo di scrittura.
Per ovviare all'inconveniente tipico dei protocolli asincroni di perdere un sacco di tempo in scambio di convenevoli tra il Master e lo Slave, l'alternativa ķ quella di definire un protocollo sincrono. L'idea ķ quella di sincronizzare le attivitÓ del Master e dello Slave sulle variazioni periodiche di un'unica variabile Clock. Sia il Master che lo Slave dovranno essere progettati e realizzati in modo da poter sempre "arrivare in tempo agli appuntamenti" definiti rispetto agli istanti di variazione della variabile Clock, secondo uno schema prestabilito. Proviamo ad abbozzare un semplice esempio basato su una variabile Clock che varia con frequenza di 20MHz, mantenendo alternativamente il valore 0 per 25ns e poi il valore 1 per 25ns. Le operazioni di lettura e scrittura potrebbero essere definite come illustrato in figura:
Come detto in precedenza, un protocollo sincrono prevede che Master e Slave siano sempre in grado di completare le loro operazioni nei tempi stabiliti, e questo a volte pu“ creare difficoltÓ ai progettisti. Per esempio, nel caso del nostro ciclo di lettura sincrono, il vincolo che deve rispettare lo slave ķ quello di produrre il dato entro 25ns dal momento in cui ha riconosciuto il comando di lettura. Tenendo conto che un modulo RAM dinamico ha normalmente tempi di accesso dell'ordine dei 50-70ns, tale vincolo sarebbe soddisfacibile solo usando moduli RAM statici (di piccole dimensioni e costosi). Normalmente, quindi, nella definizione di un qualsiasi protocollo sincrono si aggiunge un filo (di solito chiamato Ready oppure Wait) che permette allo Slave di avvisare il Master che non ķ in grado di arrivare in tempo all'appuntamento stabilito dal protocollo, e di chiedere quindi una proroga (normalmente di un intero ciclo di clock). Tale richiesta di proroga pu“ essere reiterata indefinitamente, consentendo quindi di espandere un ciclo di lettura o di scrittura con un numero arbitrario di cicli di clock aggiuntivi, fino a quando anche il pi∙ lento degli Slave non completa il suo compito. Nel nostro esempio, un eventuale modulo RAM con ritardo di 70ns potrebbe mandare la richiesta di proroga una volta, in modo da poter produrre il risultato dopo 75ns dal momento della ricezione del comando di lettura.
L'esempio riportato non intende dimostrare la maggior velocitÓ di operazione raggiungibile con un bus sincrono ben progettato rispetto ad un bus asincrono, ma vuole solo illustrare il concetto di protocollo sincrono contrapposto a quello asincrono basato su handshaking. Volendo invece fare un esempio concreto, oggi il bus di sistema che offre le migliori prestazioni tra quelli standardizzati e disponibili in sistemi commerciali ķ il cosiddetto bus PCI, nella versione 2.1. Si tratta di un bus sincrono, per il quale sono previste due frequenze di variazione del Clock: 100/3 MHz e 200/3 MHz, normalmente chiamate "33MHz" e "66MHz" (per convenzione si trascurano le cifre decimali periodiche). Il protocollo prevede il completamento di un ciclo di lettura o scrittura per ogni periodo di clock, ossia un tempo di completamento di un trasferimento di dati entro 30 oppure 15 ns. Risulta quindi evidente che tale vincolo determina un limite massimo sulla lunghezza dei fili del bus dell'ordine delle decine di cm, a causa della limitata velocitÓ di propagazione dei segnali elettromagnetici. In particolare, la versione "66MHz" ha un limite dimezzato sulla lunghezza dei fili rispetto alla pi∙ comune versione "33MHz". Lo standard PCI 2.1 prevede poi rappresentazioni dei dati su 32 bit oppure su 64 bit. Da semplici calcoli si ricava quindi che la versione "base" che si trova oggi sui personal computer ("32 bit, 33MHz") permette di leggere o scrivere dati a velocitÓ non superiori a 133 MB/s, mentre la versione "pi∙ spinta" (ossia "64 bit, 66MHz") che si pu“ oggi trovare su workstations ad alte prestazioni permette di leggere o scrivere dati a velocitÓ non superiore ai 533 MB/s.
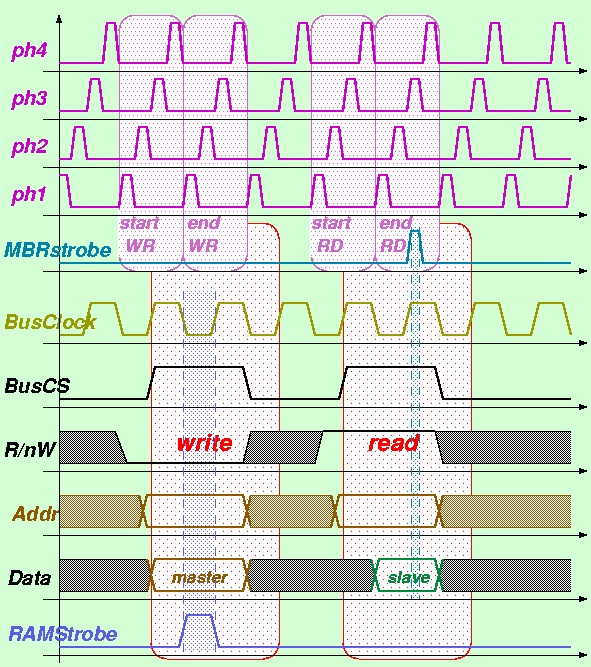
Abbiamo ora tutti gli elementi per poter completare la microarchitettura VM-1 vista in precedenza con un vero e proprio bus sincrono per la connessione tra CPU, RAM, e controller di ingresso e uscita. In particolare, definiamo un ciclo di lettura e un ciclo di scrittura entrambi basati su due cicli di Bus Clock consecutivi, come illustrato nella figura precedente. Per semplicitÓ realizzativa facciamo in modo che il Bus Clock sia sincrono con il Clock interno della CPU (anche se in generale ci“ non ķ richiesto), generando il Bus Clock a partire dal clock interno della microarchitettura VM-1 mediante il seguente Flip-flop di tipo Set-Reset:

In tal modo, il clock del bus passa a 1 all'inizio della fase 3 del clock della CPU, e torna a zero all'inizio della fase 1 del ciclo di clock successivo della CPU. La sincronia dei due clock semplifica l'interfacciamento tra la CPU ed il Bus di sistema, consentendo di mandare direttamente l'uscita RnW del registro MIR a comandare uno dei due segnali di controllo del Bus (ovviamente, il segnale R/nW del Bus). Il segnale di controllo CS del Bus di sistema deve invece essere generato a partire dall'uscita CS del registro MIR e dalle fasi 1, 2 e 3 del clock interno della CPU per mezzo del seguente circuito sequenziale:

In questo modo il segnale CS sul Bus di sistema rimane normalmente a zero per tutte le microistruzioni per le quali il campo CS del MIR vale 0, mentre passa a 1 all'inizio della fase 3 della microistruzione "startRD", e ritorna a 0 all'inizio della fase 1 della microistruzione successiva alla "endRD" (vedasi il diagramma dei segnali pi∙ avanti).
Dal punto di vista della connessione della RAM al Bus di sistema, l'operazione di lettura non pone particolari problemi di sincronizzazione, se non il fatto che il tempo di accesso in lettura del dispositivo deve essere inferiore ad un periodo completo di clock (in modo che i dati caricati nel registro MBR sul fronte di salita della fase 3 della microistruzione "endRD" siano effettivamente corrispondenti al contenuto della cella di memoria che si vuole leggere, visto che il ciclo di lettura inizia con l'inizio della fase 3 della microistruzione precedente di "startRD". In altri termini, l'operazione di lettura sul Bus sincrono viene supportata da una RAM che risponde al comando di lettura mediante un circuito combinatorio come quello di indirizzamento visto in precedenza per i moduli RAM statici, purchĶ "non troppo lento".
La corretta realizzazione della operazione di scrittura da parte della RAM richiede invece l'introduzione di un circuito sequenziale per sincronizzare il caricamento in memoria col Clock del Bus. A differenza di quanto visto in precedenza per i moduli RAM statici comandati da CS e R/nW, l'ingresso del demultiplexer le cui uscite sono connesse sugli ingressi "Strobe" dei registri che costituiscono le varie parole di RAM devono essere comandati da un signale sincronizzato al clock mediante un modulo circuitale sequenziale (chiamato "ramseq") illustrato in figura:
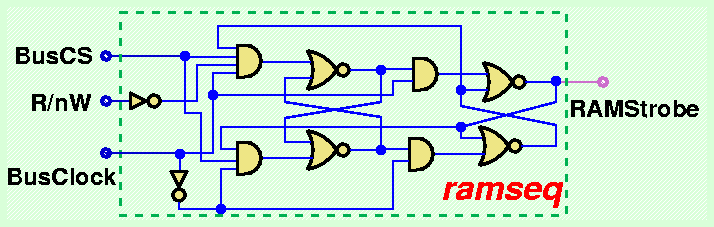
In questo modo, al latch selezionato dal demultiplexer per l'operazione di scrittura arriva un impulso di Strobe che inizia sul fronte di discesa del Bus Clock immediatamente successivo al fronte di salita del segnale BusCS e che termina sul fronte di salita del Bus Clock immediatamente successivo. Riportiamo nella seguente figura una rappresentazione schematica completa del modulo RAM per la microarchitettura VM-1:

Notare anche la disabilitazione delle uscite a tre stati del modulo RAM nel caso di lettura dagli indirizzi 4095 e 4094, ai quali deve invece rispondere il controller di ingresso e uscita per permettere alla CPU di accedere ai suoi due registri Memory-mapped.
La trattazione dei bus fino a questo punto partiva dal presupposto che nel sistema ci fosse un solo dispositivo in grado di agire come Master della comunicazione, e quindi di prendere l'iniziativa di iniziare un ciclo di lettura o scrittura inviando gli opportuni segnali CS e R/nW allo Slave da lui individuato. Nella stragrande maggioranza dei sistemi, invece, ci si trova a dover trattare casi pi∙ complessi, nei quali anche altri dispositivi, oltre alla CPU, possono agire da Master nei confronti del bus di sistema. L'esempio classico ķ quello dei trasferimenti DMA che vedremo in seguito, nei quali un controller agisce per conto della CPU per trasferire dati da RAM ad altre unitÓ (per esempio dischi) o viceversa.
La complicazione del caso in cui due o pi∙ dispositivi diversi sono predisposti per comportarsi come Master verso il bus deriva dal fatto che ciascuno di questi potrebbe prendere l'iniziativa di iniziare un ciclo di lettura o scrittura, ed occorre prendere dei provvedimenti in modo da evitare conflitti per l'uso del bus. Questo problema di coordinare l'attivitÓ dei dispositivi Master in modo che usino il bus uno alla volta senza conflitti per l'uso dei fili condivisi viene detto arbitraggio del bus. Ovviamente i dispositivi che risolvono il problema vengono detti arbitri. Cominciamo ad elencare i requisiti a cui deve soddisfare l'arbitro di un bus:
Il meccanismo normalmente adottato per realizzare un arbitro che soddisfi i requisiti elencati ķ quello della pre-assegnazione di prioritÓ diverse ai diversi Master. Le richieste vengono esaminate ed il bus viene assegnato al Master con prioritÓ pi∙ alta tra quelli che lo hanno richiesto. Una volta ottenuto il bus, un Master ne mantiene il controllo fino alla fine dell'operazione di lettura/scrittura, anche se nel frattempo arrivano altre richieste a prioritÓ maggiore (servizio non interrompibile). Il criterio di assegnazione di un valore di prioritÓ pi∙ o meno alto ad un dispositivo ai fini dell'arbitraggio del bus non ķ legato alla "importanza" del dispositivo nel sistema, bensņ alle sue esigenze in termini di tempo di risposta: vengono assegnate prioritÓ alte a dispositivi che necessitano di un accesso immediato al bus e prioritÓ pi∙ basse ai dispositivi che possono "tollerare" ritardi per l'acquisizione del bus senza comprometterne il funzionamento.
Teoricamente si potrebbe pensare di realizzare un arbitro di un bus come un unico dispositivo con tanti ingressi quanti sono i dispositivi Master (per riceverne le richieste) ed altrettante uscite (per inviare la conferma al Master che pu“ iniziare ad usare il bus). Per motivi di semplicitÓ realizzative e di economia di numero di fili, tuttavia, di solito si preferisce realizzare una versione distribuita di un arbitro a prioritÓ, detta realizzazione "daisy-chain". Un possibile schema di realizzazione di arbitro Daisy-chain ķ illustrato in figura:
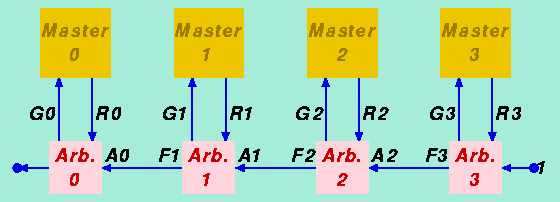
Questo schema ķ concepito per integrarsi in un bus di tipo sincrono, dove in una certa fase di clock i vari Master possono avanzare la loro richiesta di uso del bus, e nella fase successiva di clock il sistema di arbitraggio daisy-chain da il consenso all'uso ad uno solo di questi, anche in presenza di richieste multiple. In particolare ci focalizziamo sulla progettazione del circuito combinatorio di arbitraggio, supponendo che i segnali di richiesta dei Master sia opportunamente sincronizzati al clock del bus mediante l'uso di registri (flip-flop). Anche il periodo di effettiva utilizzazione del bus dal parte del Master che ha ottenuto il consenso dovrÓ seguire un protocollo predefinito, secondo quanto discusso in precedenza.
Ciascun Master (i) ķ collegato ad un proprio Arbitro (i) mediante un filo di richiesta Ri (1=richiesta, 0=non serve il bus) ed un filo di concessione del bus Gi (1=puoi diventare Master del bus, 0=devi aspettare). L'i-esimo arbitro riceve una abilitazione Ai dall'arbitro a prioritÓ immediatamente superiore (i+1) (Ai=1 significa "se il tuo Master chiede il bus glielo puoi concedere subito"; Ai=0 significa "se il tuo Master chiede il bus devi farlo aspettare"). In oltre, l'i-esimo arbitro manda in uscita all'arbitro a prioritÓ immediatamente inferiore una segnalazione circa la disponibilitÓ del bus Fi (1=il bus pu“ essere assegnato a Master di prioritÓ inferiore, 0=il bus ķ giÓ stato assegnato ad un Master di prioritÓ maggiore o uguale ad i).
La connessione Daisy-chain consente di far correre un solo filo tra un arbitro e l'altro, riducendo quindi la complessitÓ delle connessioni del bus (ciascun dispositivo Master, in realtÓ, viene realizzato integrando anche il suo Arbitro. SarÓ la disposizione fisica dei dispositivi sulle connessioni del bus a determinare implicitamente la prioritÓ di arbitraggio; nell'esempio in figura i dispositivi hanno prioritÓ crescenti da sinistra verso destra.
L'uso di molti dispositivi all'interno di un sistema di calcolo prevede il trasferimento di quantitÓ notevoli di informazioni da/verso la memoria RAM. Esempi tipici sono i dispositivi di comunicazione in rete che prevedono la trasmissione e la ricezione di messaggi e le unitÓ a disco (magnetico, ottico, ecc.). Tipicamente l'uso efficente di questi dispositivi prevede il trasferimento di "blocchi" di dati codificati in molte celle di memoria di indirizzo consecutivo. Ovviamente il trasferimento di dati tra il "drive" di un dispostivo e la memoria potrebbe essere effettuato dalla CPU mediante l'esecuzione di un apposito programma che legge un dato alla volta dalla RAM o da un registro del drive, lo copia in un suo registro interno, lo riscrive in un registro del drive o in una cella di RAM, e ripete la sequenza di lettura e riscrittura fin quando l'intero blocco di dati non ķ stato trasferito. Tale realizzazione (normalmente detta mediante "programmed I/O") risulta per“ gravemente inefficente per diversi motivi che approfondiremo in seguito. Una alternativa decisamente superiore dal punto di vista della velocitÓ di completamento del trasferimento e di uso equilibrato dei dispositivi dontenuti nel sistema di calcolo ķ il cosiddetto Direct Memory Access (DMA) da parte del drive del dispositivo coinvolto nell'operazione.
L'idea di base di un trasferimento DMA ķ quella di dotare il drive di un dispositivo della capacitÓ di indirizzare la memoria RAM per realizzare delle sequenze di cicli di lettura o di scrittura. Quando l'esecuzione di un programma da parte della CPU richiede un trasferimento di dati tra la RAM ed il dispositivo, la CPU si limita a "programmare" il trasferimento mandando un opportuno comando al drive nel quale viene specificato l'indirizzo della prima cella di memoria coinvolta, il numero totale di celle da trasferire, e la direzione del trasferimento (dal dispositivo verso la RAM o viceversa). Fatto questo, la CPU pu“ procedere oltre nell'esecuzione del programma (ovviamente senza poter far affidamento sul fatto che il trasferimento sia stato completato), e sarÓ il drive del dispositivo a portare a termine effettivamente il trasferimento in modalitÓ DMA. Per fare questo, il drive dovrÓ poter diventare Master del bus in alternativa alla CPU. Quindi la realizzazione di un sistema che ammette l'uso di trasferimenti DMA richiede un opportuno protocollo di arbitraggio per il bus, come abbiamo visto in precedenza.
Nei sistemi di calcolo reali, il concetto di trasferimento DMA viene di solito realizzato in due modi diversi: mediante l'uso di canali DMA oppure di tecniche di Bus Mastering. La seconda alternativa corrisponde ad una realizzazione piena dell'idea di trasferimento DMA cosņ come illustrata sopra in termini intuitivi, mentre la prima ne costituisce una approssimazione, caratterizzata da alcune limitazioni di funzionalitÓ che consentono un risparmio nella complessitÓ di realizzazione.
Un canale DMA sostituisce la CPU nel trasferimento dei dati tra memoria e drive del dispositivo. Normalmente a livello di sistema vengono definiti uno o pi∙ canali DMA, che sono dei semplici "co-processori" specializzati nel trasferimento di dati, ma non legati a nessun particolare drive di dispositivi. La CPU programma un canale DMA specificando, oltre ai parametri relativi agli indirizzi di RAM, anche l'identificazione del registro del drive nel/dal quale scrivere/leggere i dati. Il drive stesso si comporta da Slave negli accessi ai sui registri operati dal canale DMA. ╔ il canale DMA e non il drive del dispositivo che "compete con la CPU" per diventare Master del bus. Con uno schema realizzativo di questo tipo, l'aggiunta di nuovi drive connessi al bus non richiede complicazioni nell'arbitraggio del bus.
Un drive con capacitÓ di Bus Mastering puo“ invece essere programmato dalla CPU per diventare lui stesso Master del bus ed effettuare i trasferimenti DMA, senza dover far affidamento su nessun "canale" esterno. Quindi ogni drive deve contenere al suo interno la logica di indirizzamento della memoria e di interfacciamento con l'arbitro del bus. L'aggiunta di un nuovo drive nel sistema aumenta il numero di potenziali Master del bus, e pu“ quindi essere realizzata in modo semplice e modulare solo utilizzando una tecnica di arbitraggio distribuita tipo daisy-chain.
Dal punto di vista delle prestazioni ottenibili, possiamo analizzare l'utilizzazione che viene fatta del bus di sistema per arrivare a stabilire che il trasferimento DMA di tipo Bus Mastering ķ il pi∙ efficente, mentre il trasferimento di tipo Programmed I/O ķ il meno efficente. Infatti, nella modalitÓ Bus Mastering, il trasferimento (lettura o scrittura) di una cella di memoria "costa" un solo ciclo di lettura o scrittura (operato dal drive dopo aver ottenuto dall'arbitro del bus il consenso ad agire come Master); nella modalitÓ Canale DMA lo stesso trasferimento costa sempre un ciclo di lettura pi∙ un ciclo di scrittura (il canale deve prima ottenere il valore dalla RAM o dal registro del drive, e poi riscrivere lo stesso valore nel registro del drive o in una cella di RAM); infine nella modalitÓ Programmed I/O, oltre ai due cicli di lettura e scrittura del caso Canale DMA (stavolta operati dalla CPU), dobbiamo anche contare il/i ciclo/i di lettura necessari(o) per effettuare il fetch delle istruzioni eseguite dalla CPU.
Focalizzandoci dunque sul DMA di tipo Bus Mastering, possiamo ulteriormente distinguere almeno due modalitÓ diverse di realizzazione: